Getting started
To follow along, start by installing the required packages:BRAINTRUST_API_KEY as an environment variable:
Exporting your API key is a best practice, but to make it easier to follow along with this cookbook, you can also hardcode it into the code below.
Approaches to web navigation
There are a few ways AI models can navigate websites:- HTML-only: Uses page structure but misses visual details.
- Screenshot-only: Captures visuals but misses interaction details.
- Multimodal: Combines HTML structure and screenshots for better decisions.
Processing screenshots
First, let’s write a function that converts screenshots of a given webpage into a format that we can use to pass to our model and attach to our eval.Keeping track of actions
Models perform better if they have context from previous steps. Without historical context, an agent might repeat actions or select incorrect next steps. This function takes the latest few actions (up toMAX_PREVIOUS_ACTIONS) and neatly formats them for easy reference:
CLICK, TYPE, or SELECT), and any associated values (like text typed):
Loading and preparing the dataset
Now that we’ve set up our helper functions, we can we load and process samples from the Multimodal-Mind2Web dataset:Building the prediction function
Next, we’ll build the prediction function that will send each formatted input to the model (gpt-4o) and retrieve the predicted action:
Defining our scorers
To evaluate how accurate the predictions are against the ground truth, we’ll use two different scoring metrics. For web navigation tasks, we need metrics that can pinpoint specific strengths and weaknesses in our agent. We’ll create two simple code-based scorers. The first scorer checks if the predicted action matches the expected action type:Running the evaluation
Now that we’ve set up the task, dataset, and evaluation criteria, we’re ready to run our evaluation. This function will load and process each dataset sample, generate predictions, and assess how accurately the model identifies the correct action type and associated details. All results will be captured in Braintrust, allowing us to analyze performance and pinpoint areas for improvement.Analyzing the results
Web agents have many configuration options that can impact their performance. In Braintrust, you can dig deeper into each trace to see each step the agent takes, including attachments and intermediate processing steps. This makes it easier to identify issues, debug quickly, and iterate.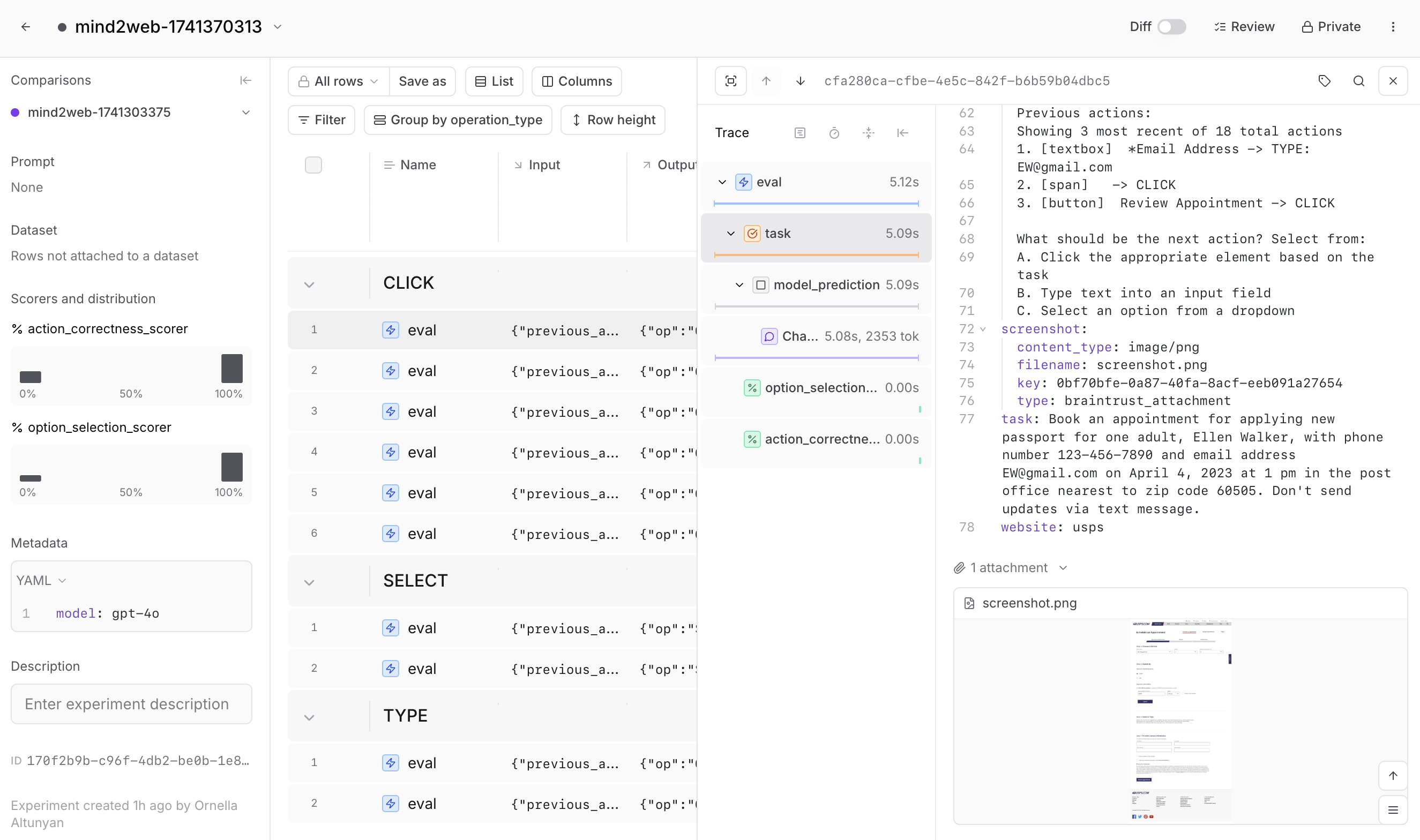
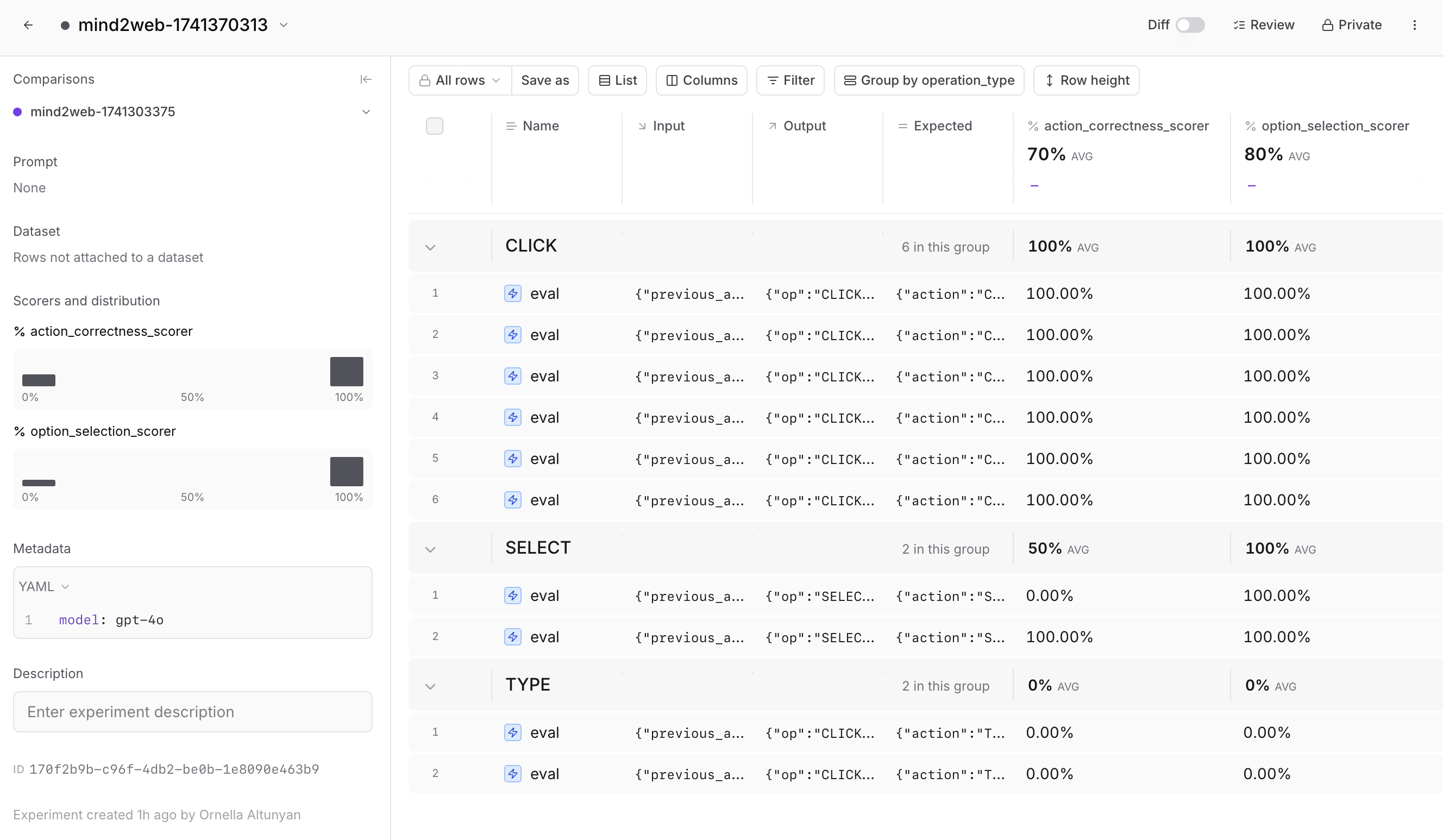
Learning from the data
Taking the time to analyze your results in Braintrust will help you discover clear opportunities to improve your agent. For example, you might find that certain HTML preprocessing techniques perform better on form-intensive websites, or that providing more detailed historical context improves accuracy on complex tasks. By tracing each action, filtering results, and comparing different approaches systematically, you can make targeted improvements instead of relying on guesswork.Next steps
Now that you’ve explored how to evaluate the decision making ability of a web agent, you can:- Learn more about how to evaluate agents
- Check out the guide to what you should do after running an eval
- Try out another agent cookbook