Contributed by Ankur Goyal on 2024-07-26
LLaMa 3.1 is distributed as an instruction-tuned model with 8B, 70B, and 405B parameter variants. As part of the release, Meta mentioned that
These are multilingual and have a significantly longer context length of 128K, state-of-the-art tool use, and overall stronger reasoning capabilities.Let’s dig into how we can use these models with tools, and run an eval to see how they compare to gpt-4o on a benchmark.
Setup
You can access LLaMa 3.1 models through inference services like Together, which has generous rate limits and OpenAI protocol compatibility. We’ll use Together, through the Braintrust proxy to access LLaMa 3.1 and OpenAI models. To get started, make sure you have a Braintrust account and an API key for Together and OpenAI. Make sure to plug them into your Braintrust account’s AI secrets configuration and acquire a BRAINTRUST_API_KEY. Feel free to put your BRAINTRUST_API_KEY in a.env.local file next to this notebook, or just hardcode it into the code below.
A real use case: LLM-as-a-Judge evaluators that make tool calls
At Braintrust, we maintain a suite of evaluator functions in the Autoevals library. Many of these evaluators, likeFactuality, are “LLM-as-a-Judge”
evaluators that use a well-crafted prompt to an LLM to reason about the quality of a response. We are big fans of tool calling, and leverage it extensively in autoevals to make it easy and reliable
to parse the scores and reasoning they produce.
As we change autoevals, we run evals to make sure we improve performance and avoid regressing key scenarios. We’ll run some of our autoeval evals as a way of assessing how well LLaMa 3.1 stacks up to gpt-4o.
Here is a quick example of the Factuality scorer, a popular LLM-as-a-Judge evaluator that uses the following prompt:
Running evals
We use a subset of the CoQA dataset to test the Factuality scorer. Let’s load the dataset and take a look at an example.GPT-4o
Let’s run a full eval with gpt-4o, LLaMa-3.1-8B, LLaMa-3.1-70B, and LLaMa-3.1-405B to see how they stack up. Since the evaluator generates a number between 0 and 1, we’ll use theNumericDiff scorer to assess accuracy, and a custom NonNull scorer to measure how many invalid tool calls are generated.

LLama-3.1-8B, 70B, and 405B
Now let’s evaluate each of the LLaMa-3.1 models.Analyzing the results: LLaMa-3.1-8B
Ok, let’s dig into the results. To start, we’ll look at how LLaMa-3.1-8B compares to GPT-4o.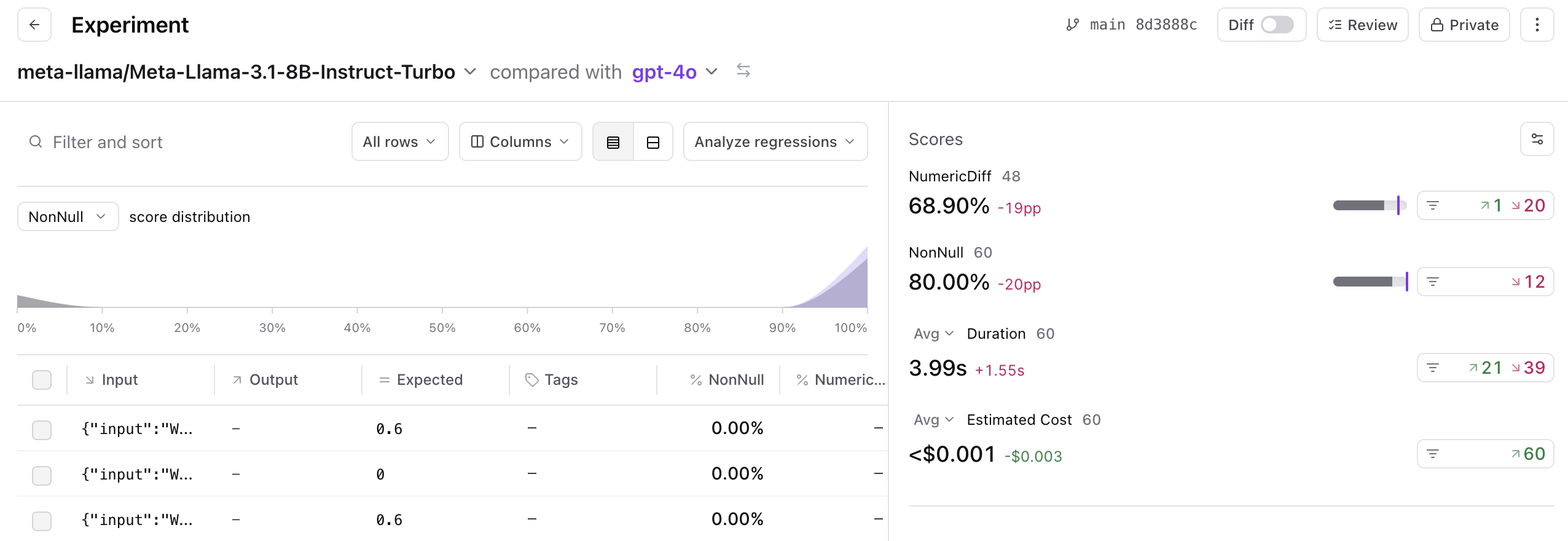
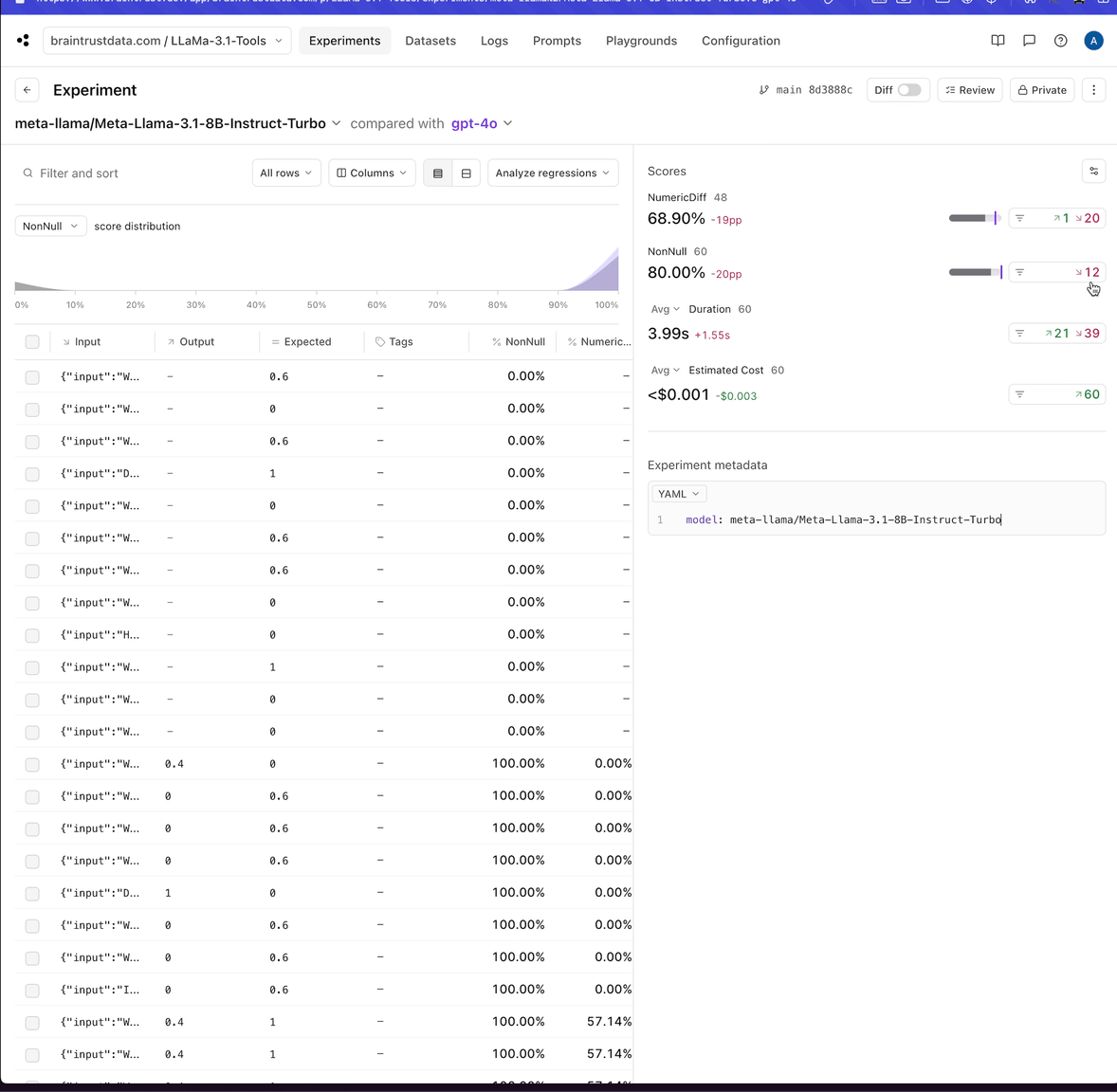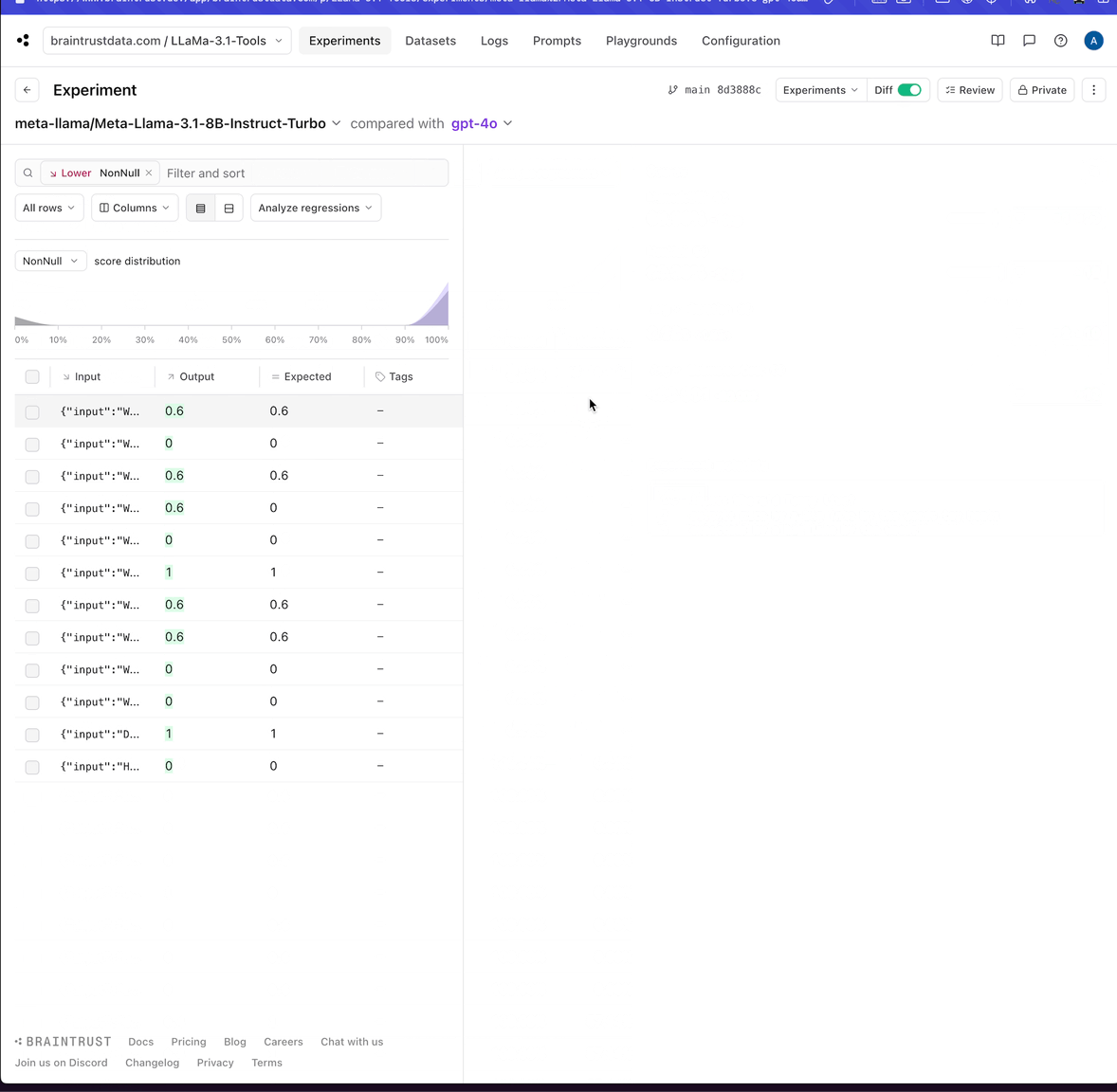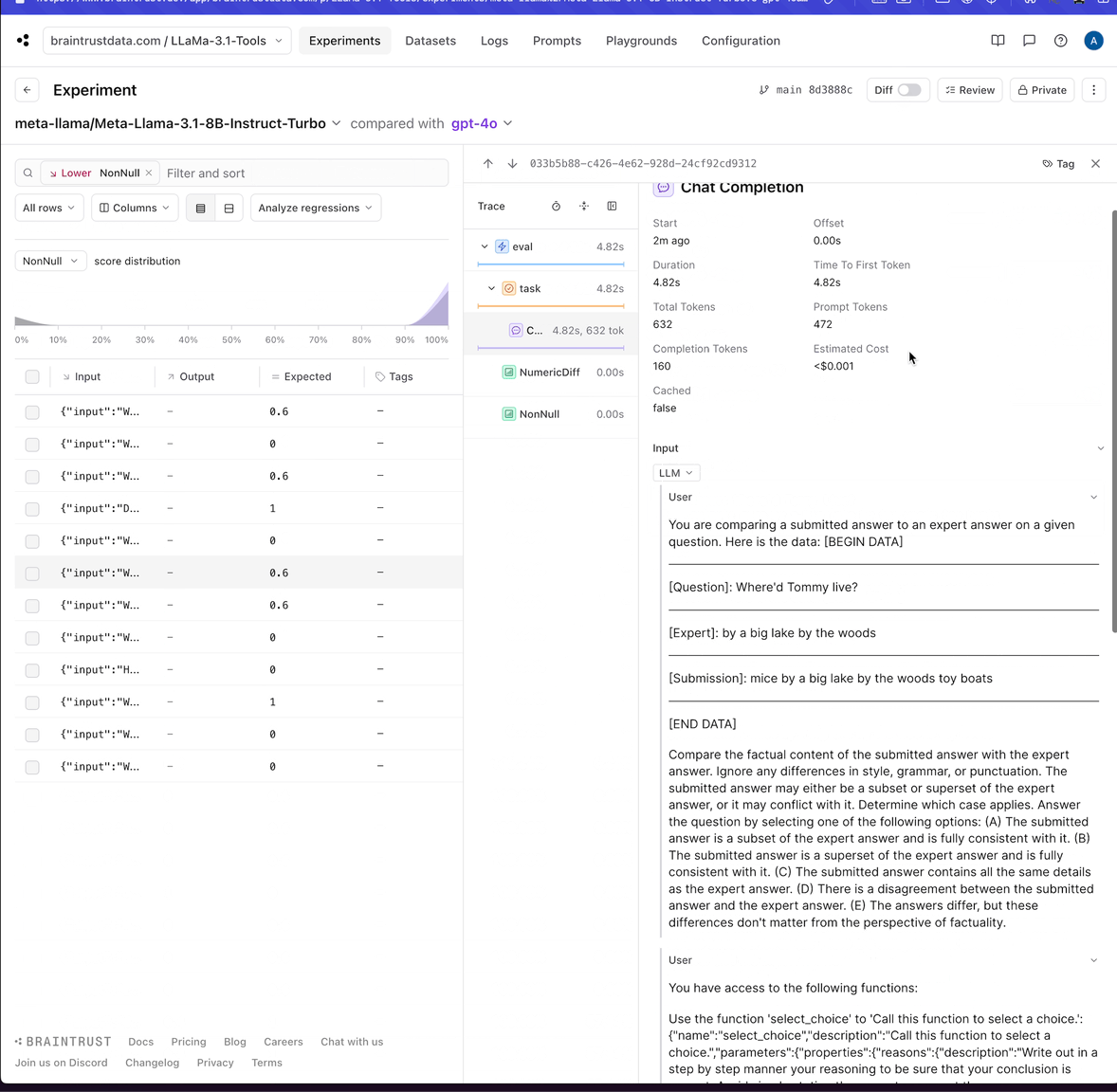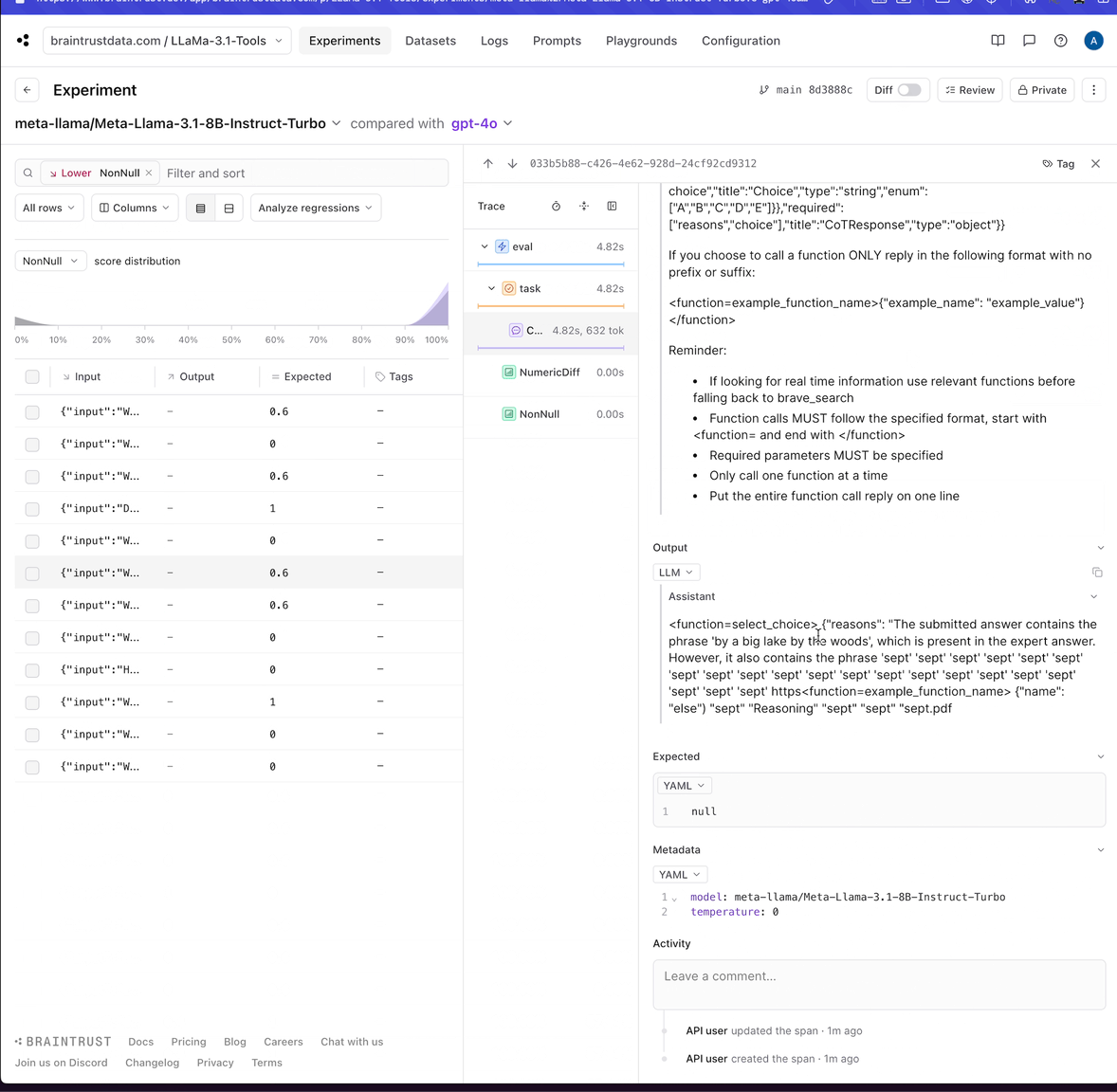
Analyzing all models
If we look across models, we’ll start to see some interesting takeaways.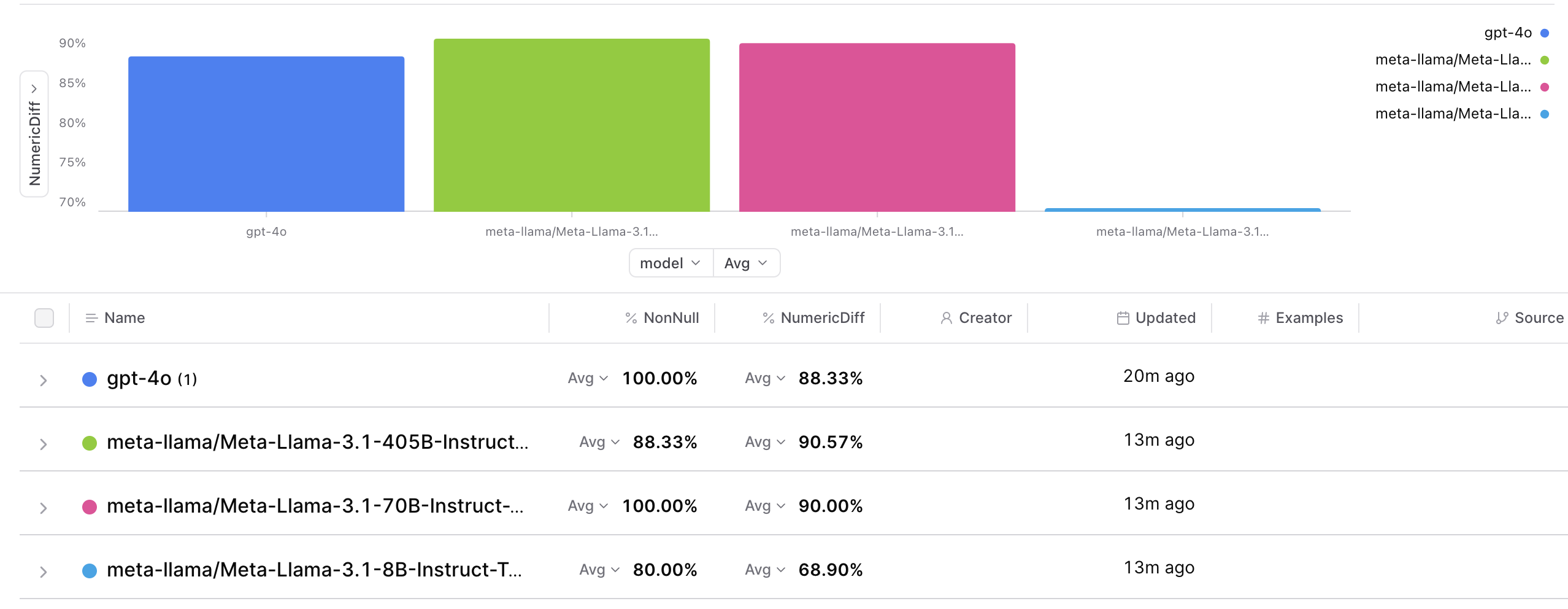
- LLaMa-3.1-70B has no parsing errors, which is better than LLaMa-3.1-405B!
- Both LLaMa-3.1-70B and LLaMa-3.1-405B performed better than GPT-4o, although by a fairly small margin.
- LLaMa-3-70B is less than 25% the cost of GPT-4o, and is actually a bit better.
Where to go from here
In just a few minutes, we’ve cracked the code on how to perform tool calls with LLaMa-3.1 models and run a benchmark to compare their performance to GPT-4o. In doing so, we’ve found a few specific areas for improvement, e.g. parsing errors for tool calls, and a surprising outcome that LLaMa-3.1-70B is better than both LLaMa-3.1-405B and GPT-4o, yet a fraction of the cost. To explore this further, you could:- Expand the benchmark to measure other kinds of evaluators.
- Try providing few-shot examples or fine-tuning the models to improve their performance.
- Play with other models, like GPT-4o-mini or Claude to see how they compare.