Evaluating agents
This blog post is a companion guide to Anthropic's research on building effective agents. It requires prior knowledge of agentic systems.
Building an agentic system, whether it’s a simple augmented large language model (LLM) or a fully autonomous agent, involves many moving parts. Your design might make sense on paper, but without measurement and iterative improvement, unexpected issues can pop up in production. Inspired by Anthropic’s guide to building effective agents, in this post, we’ll walk through practical strategies for evaluating the quality and accuracy of agentic systems.
Why run evaluations?
LLM-based agents:
- Can have unpredictable error modes (hallucinations, repetitive loops, etc). For example, a financial advisory chatbot might hallucinate stock market predictions based on fictional data, potentially misleading users.
- Can rely on context, memory, or retrieval tools that may have their own failures. For example, a legal research assistant might misinterpret a poorly retrieved document and provide incorrect case law summaries.
- Iteratively refine their own outputs, which can hide the root cause of an error. For example, a content generation tool might produce a misleading statement in an early draft, then repeatedly refine and expand on it, amplifying the inaccuracy in the final version.
Evals help you detect and debug these issues before they impact your users. They can also help you decide how you might improve your application.
Choosing eval metrics
Because agentic systems can be extremely complex, there’s no one-size-fits-all set of metrics, but we’ll explore an example of an agent and a potential set of scorers for each pattern defined in the guide to building effective agents. Metrics refer to the quantitative or qualitative measures used to evaluate how well the agent performs against its intended objectives, while scorers are the code-based or LLM-as-a-judge functions used to calculate these metrics. Like the guide, we’ll start simple and increase in complexity. Think of each set of scorers as a menu to pick and choose from depending on your specific system’s goals and constraints.
Quantitative vs. qualitative metrics
Quantitative metrics help track performance over time and compare different implementations. Some examples include accuracy against a test dataset, average cost per request, or average response latency. These metrics measure LLM behaviors with standardized checks. Scorers for these metrics are logical and deterministic. Qualitative metrics measure whether the agent is achieving the desired experience for the end user. These usually come from user feedback or support tickets, and require some sort of human review or LLM-as-a-judge analysis. These qualitative checks capture nuances that raw metrics can miss. Scorers for these metrics can measure things like trends, "vibes", or lagging indicators.
In many cases, you’ll want both. For example, you might track how often your agent successfully handles a customer request and measure user satisfaction with the agent’s helpfulness.
Iterative evaluation process
Generally, a reasonable first pass at evaluating any agent is to start by looking at the final output. This gives a high-level view of the agent’s performance. If you notice failure points, you can go deeper on a particular intermediate step and add more evaluations, until you build a comprehensive eval system. You might find that you need more granular evals for things like:
- Behavioral patterns - step-by-step decisions
- Tool effectiveness - how well the agent uses specific tools or APIs
- Cost efficiency - monitoring resource usage over multiple iterations
Building block: the augmented LLM
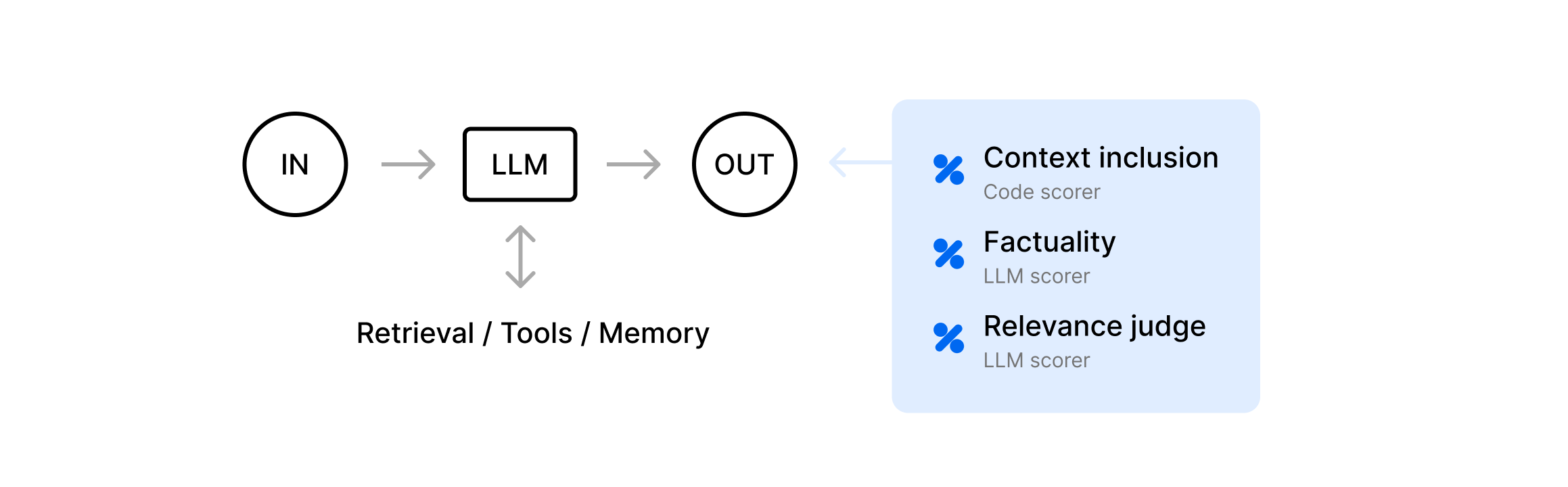
- First, the LLM decides whether it needs data from an external knowledge base or a particular tool.
- If retrieval or a tool call is needed, we append the results to our prompt so the next LLM call can incorporate that new info.
- Finally, we ask the LLM to generate the “real” output for the user or system, updating our memory with the final result in case future steps rely on it.
For example, a user asks for a recipe for grilled chicken. The question is embedded and an agent retrieves recipes from NYT Cooking related to the embedded terms. The retrieved context is fed to the LLM as context, and the LLM provides an output to the user.
ContextInclusion- check if the final LLM output string contains a required keyword or phrase, indicating that it successfully incorporated the retrieved context. Since the point of an augmented LLM is to show that it used external information effectively, the augmentation step is wasted if the final output ignores the external information.
async function contextInclusion({
output,
expected,
}: {
output: string;
expected?: {
requiredContext?: string;
};
}): Promise<number | null> {
if (!expected?.requiredContext) {
// If there's no requiredContext, we skip scoring
return null;
}
return output.includes(expected.requiredContext) ? 1 : 0;
}
Factuality- use the Factuality scorer from autoevals, or use it as a starting point and add your own custom logic. Augmentation is supposed to reduce hallucinations by leveraging real data, soFactualitymakes sure that the retrieval actually improved correctness.
In this code snippet, we also show how to run an evaluation on Braintrust via the SDK using the Factuality scorer. For more information, check out the documentation.
// Example dataset and evaluation
braintrust.Eval("Recipe Retrieval Factuality", {
data: () => [
{
input: "Can you give me a recipe for grilled chicken?",
expected: `Sure! Here's a recipe for grilled chicken:
1. Marinate the chicken in a mixture of olive oil, lemon juice, garlic, salt, and pepper for at least 30 minutes.
2. Preheat the grill to medium-high heat.
3. Place the chicken on the grill and cook for about 6-8 minutes per side, until fully cooked (internal temperature of 165°F).
4. Let the chicken rest for a few minutes before serving. Enjoy!`,
metadata: {
source: "NYT Cooking - Simple Grilled Chicken",
},
},
{
input: "How long should I marinate chicken for grilling?",
expected: `For best results, marinate chicken for at least 30 minutes to 2 hours. This allows the flavors to penetrate the meat. Avoid marinating for longer than 24 hours as the texture may become mushy.`,
metadata: {
source: "NYT Cooking - Simple Grilled Chicken",
},
},
{
input: "What sides go well with grilled chicken?",
expected: `Grilled chicken pairs well with sides like roasted vegetables, a fresh green salad, mashed potatoes, or grilled corn on the cob. For a lighter option, try a quinoa salad or steamed asparagus.`,
metadata: {
source: "NYT Cooking - Weeknight Dinner Guide",
},
},
],
task: async (input: string) => {
// This is where you'd make your actual LLM call
// For demo purposes, we'll return hardcoded responses
const responses: Record<string, string> = {
"Can you give me a recipe for grilled chicken?": `Here's a simple grilled chicken recipe:
1. Marinate chicken with olive oil, garlic, lemon juice, and spices.
2. Grill over medium-high heat for 6-8 minutes per side until cooked through.
3. Let rest before serving.`,
"How long should I marinate chicken for grilling?": `It's recommended to marinate chicken for 30 minutes to 2 hours for optimal flavor. Avoid over-marinating.`,
"What sides go well with grilled chicken?": `Popular sides include roasted vegetables, salads, mashed potatoes, or grilled corn. Lighter options include quinoa salad or asparagus.`,
};
return (
responses[input] || "I don't have information about that recipe request."
);
},
scores: [Factuality],
});
RelevanceJudge- qualitatively judge if the solution is relevant and using the retrieved info correctly. Sometimes, an LLM might parrot key words without actually understanding the user’s input.
const RelevanceJudge = LLMClassifierFromTemplate({
name: "Relevance Judge",
promptTemplate: `
Read the user's question and the system's final output.
Does the final output directly address the question by using the retrieved context?
Question: {{input}}
Output: {{output}}
Respond "Y" if relevant, "N" if not.
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: false,
});
Prompt chaining
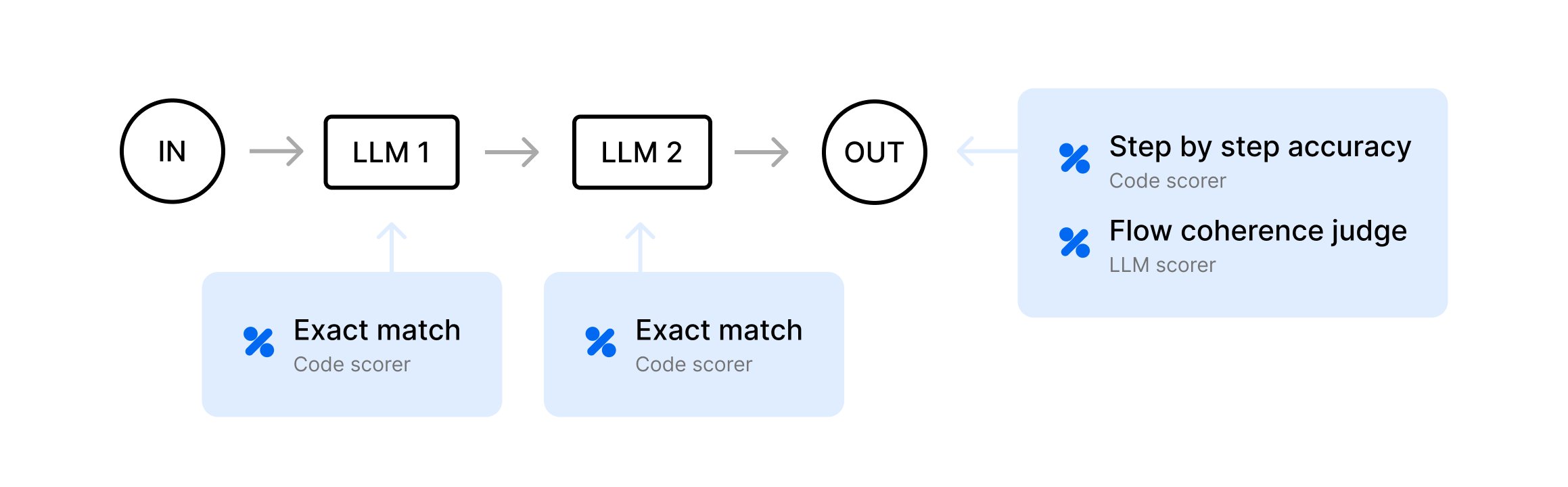
A fixed series of LLM calls:
- Summarize
- Draft
- Refine
- And so on
For example, an agent first summarizes a user’s text, then writes a short draft, and finally refines it.
ExactMatch- compare the output to an “expected” output. If each chain step is very structured or requires exact text, a simple “exact match” or “string similarity” at each step can be quite effective.
You could also use ExactMatch from autoevals.
async function ExactMatch({
output,
expected,
}: {
output: string;
expected?: string;
}): Promise<number | null> {
// Skip the test if there's no expected output
if (!expected) {
return null;
}
return output.trim() === expected.trim() ? 1 : 0;
}
StepByStepAccuracy— instrument metadata such as a boolean for each step that checks the accuracy, then check the accuracy of the final output. In prompt chaining, upstream errors cascade. Checking each step ensures you can pinpoint exactly where the chain fails.
async function StepByStepAccuracy({
output,
metadata,
}: {
output: string;
metadata?: {
summaryCheck?: boolean;
};
}): Promise<number | null> {
// Suppose we stored a boolean in metadata.summaryCheck indicating if Step 1 was correct
if (metadata?.summaryCheck === undefined) {
// No info, skip
return null;
}
// We can combine step correctness with final output checks.
// For example, if step1 was correct => +0.5, final output is non-empty => +0.5
let score = 0;
if (metadata.summaryCheck) score += 0.5;
if (output.trim().length > 0) score += 0.5; // Trivial final check
return score; // Yields 0, 0.5, or 1
}
FlowCoherenceJudge— read each step and decide if the chain logically flows and improves by the end. Some tasks require a more subjective measure. This is a good first step if you aren’t ready to incorporate human review.
const FlowCoherenceJudge = LLMClassifierFromTemplate({
name: "Flow Coherence Judge",
promptTemplate: `
We have a 3-step prompt chain:
Step1: Summarize user input
Step2: Draft
Step3: Refine
Final output: {{output}}
Do these steps seem coherent and produce a final result that matches the original request?
Answer "Y" or "N".
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: false,
});
Routing
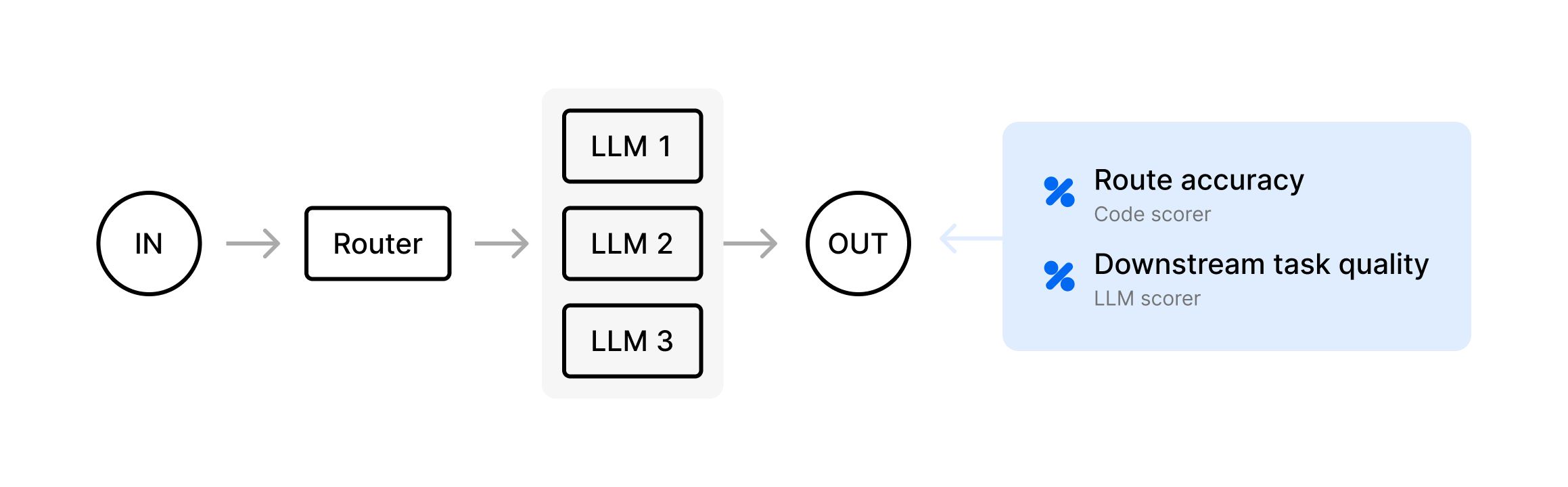
- The system classifies user inputs into distinct routes
- Each route has its own specialized logic or sub-prompt
- If the agent picks the wrong route, the final output is likely incorrect
For example, an agent reads a customer request like “I want my money back” and decides whether to use the Refund flow or the General Inquiry flow.
RouteAccuracy- checks if the agent’s chosen route (found inoutput) matches theexpectedroute label. If the wrong route is chosen at the start, the final answer will be wrong.
async function RouteAccuracy({
output,
expected,
}: {
output: string;
expected?: string;
}): Promise<number | null> {
// Skip if we don't know the correct route
if (!expected) {
return null;
}
// Score 1 if the agent's route in the output matches the expected route
return output.includes(expected) ? 1 : 0;
}
DownstreamTaskQuality- qualitatively checks whether, after picking a route, the final response actually solves the user’s problem. If you have a super nuanced set of routes, like multiple categories of customer support, an LLM might be better at determining accuracy than code.
const DownstreamTaskQuality = LLMClassifierFromTemplate({
name: "Downstream Task Quality",
promptTemplate: `
User request: {{input}} Agent output: {{output}}
Does the final answer appropriately resolve the user's request given the chosen route? Answer "Y" for yes, "N" for no.
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: false,
});
Parallelization
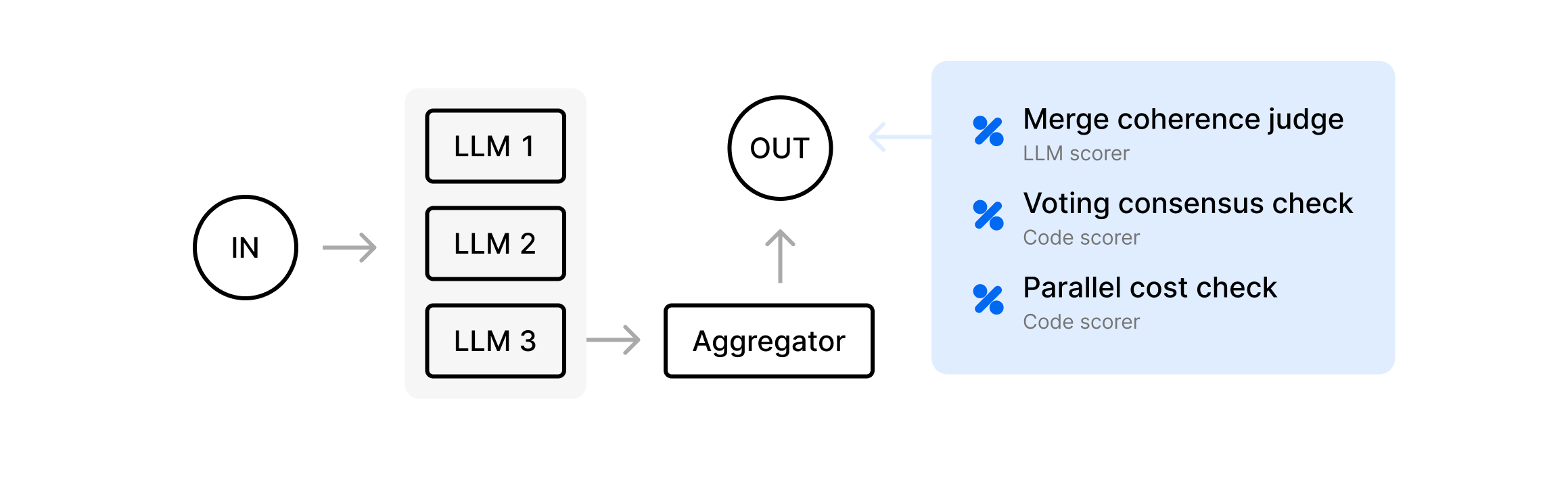
Multiple LLM calls happen at once, either:
- Each doing a different section of a task
- Producing multiple candidate outputs and then “voting” on the best
The final step merges or selects from these parallel results.
For example, an agent splits a long text into two halves, processes each half with a separate LLM call, then merges them into a single summary.
MergeCoherenceJudge- uses an LLM to see if the combined sections produce a cohesive final text. Merging partial outputs can lead to repetition or writing styles that aren't combined cohesively.
const MergeCoherenceJudge = LLMClassifierFromTemplate({
name: "Merge Coherence Judge",
promptTemplate: `
Merged output from parallel tasks: {{output}}
Does this text read coherently without major repetition or gaps? Reply "YES" or "NO".
`,
choiceScores: {
YES: 1,
NO: 0,
},
useCoT: false,
});
VotingConsensusCheck- if the system collects multiple candidates, check how many of them match the final chosen answer. If the final answer was “voted in,” it’s important to measure how strongly the candidates agreed.
async function VotingConsensusCheck({
output,
metadata,
}: {
output: string;
metadata?: {
candidates?: string[];
};
}): Promise<number | null> {
// Skip if there are no candidates in metadata
if (!metadata?.candidates) {
return null;
}
const final = output.trim();
// Count how many candidates match the final output
const matches = metadata.candidates.filter((c) => c.trim() === final).length;
// Return the fraction of matches from 0 to 1
return matches / metadata.candidates.length;
}
ParallelCostCheck- returns 1 if the total token usage for parallel calls did not exceed a threshold. Parallelization can balloon your token usage. This lets you keep an eye on cost-performance tradeoffs.
async function ParallelCostCheck({
metadata,
}: {
output: string;
metadata?: {
model: string;
max_tokens: number;
temperature: number;
top_p: number;
prompt_tokens: number;
completion_tokens: number;
};
}): Promise<{
name: string;
score: number;
metadata: { totalTokens: number; maxTokens: number };
} | null> {
// Skip if any required metadata is missing
if (
!metadata?.max_tokens ||
!metadata?.prompt_tokens ||
!metadata?.completion_tokens
) {
return null;
}
const totalTokens = metadata.prompt_tokens + metadata.completion_tokens;
return {
name: "parallel_cost",
score: totalTokens <= metadata.max_tokens ? 1 : 0,
metadata: { totalTokens, maxTokens: metadata.max_tokens },
};
}
Orchestrator-workers
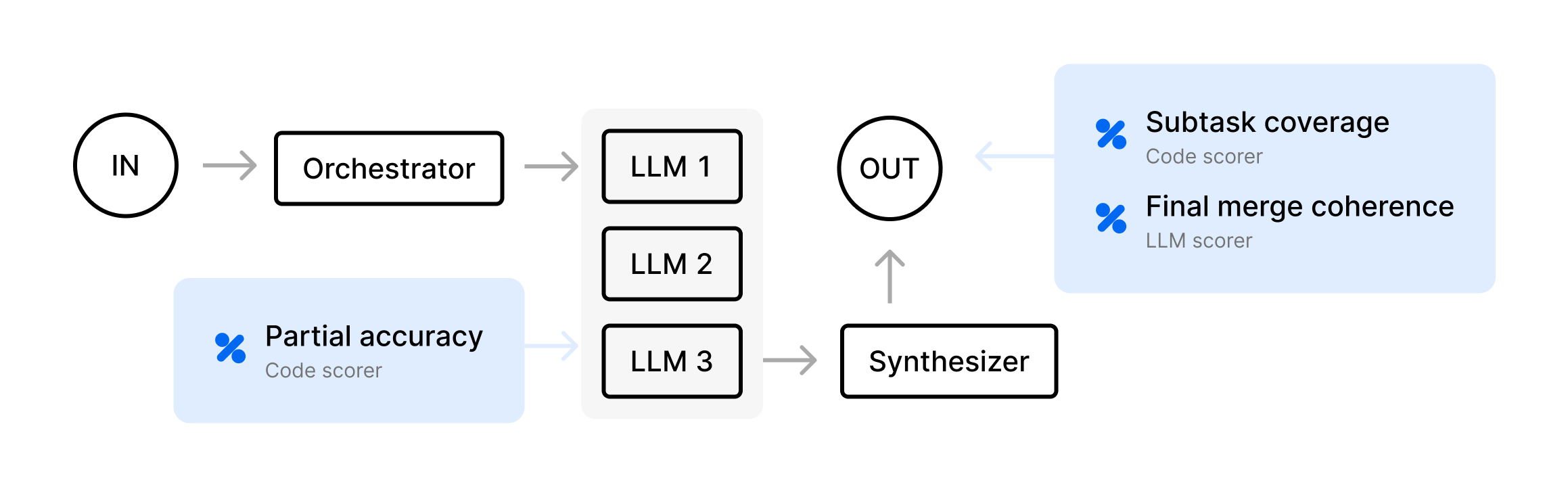
- An “orchestrator” LLM breaks a large or ambiguous request into subtasks
- “Worker” LLMs each handle a subtask, returning partial outputs
- The orchestrator merges them into a final result
For example, an agent breaks a coding request into multiple file edits, each file handled by a different worker, and then merges them into a single pull request.
SubtaskCoverage- checks if the final result includes all required subtasks (listed inexpected.subtasks). If the orchestrator is supposed to handle["Implement function A","Implement function B"]but the final text doesn’t mention function B, we fail.
async function SubtaskCoverage({
output,
expected,
}: {
output: string;
expected?: {
subtasks?: string[];
};
}): Promise<number | null> {
// Skip if no subtasks are provided in expected
if (!expected?.subtasks) {
return null;
}
// Check if any subtask is missing from the final output
const missing = expected.subtasks.some((task) => !output.includes(task));
return missing ? 0 : 1;
}
PartialAccuracy- scores the correctness of each “worker” subtask, stored inmetadata.workerOutputs. Each subtask might have a known correct snippet. This helps you pinpoint whether specific workers performed well.
async function PartialAccuracy({
metadata,
}: {
metadata?: {
workerOutputs?: Array<{
partialOutput: string;
expectedPartial?: string;
}>;
};
}): Promise<number | null> {
// Skip if no worker outputs are provided
if (!metadata?.workerOutputs) {
return null;
}
let total = 0;
let count = 0;
for (const w of metadata.workerOutputs) {
if (!w.expectedPartial) {
continue;
}
count++;
if (w.partialOutput.trim() === w.expectedPartial.trim()) {
total++;
}
}
// If no workers had expectedPartial, skip scoring
if (count === 0) {
return null;
}
// Return the fraction of correct partial outputs (0 to 1)
return total / count;
}
FinalMergeCoherence- checks if the orchestrator’s final merge step produced a cohesive, non-redundant result. Even if each worker subtask is correct, the final step might accidentally produce a contradictory result.
const FinalMergeCoherence = LLMClassifierFromTemplate({
name: "Final Merge Coherence",
promptTemplate: `
We have a final merged output:
{{output}}
Does this final text show a cohesive combination of all subtasks without contradictions?
Answer Y or N.
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: false,
});
Evaluator-optimizer
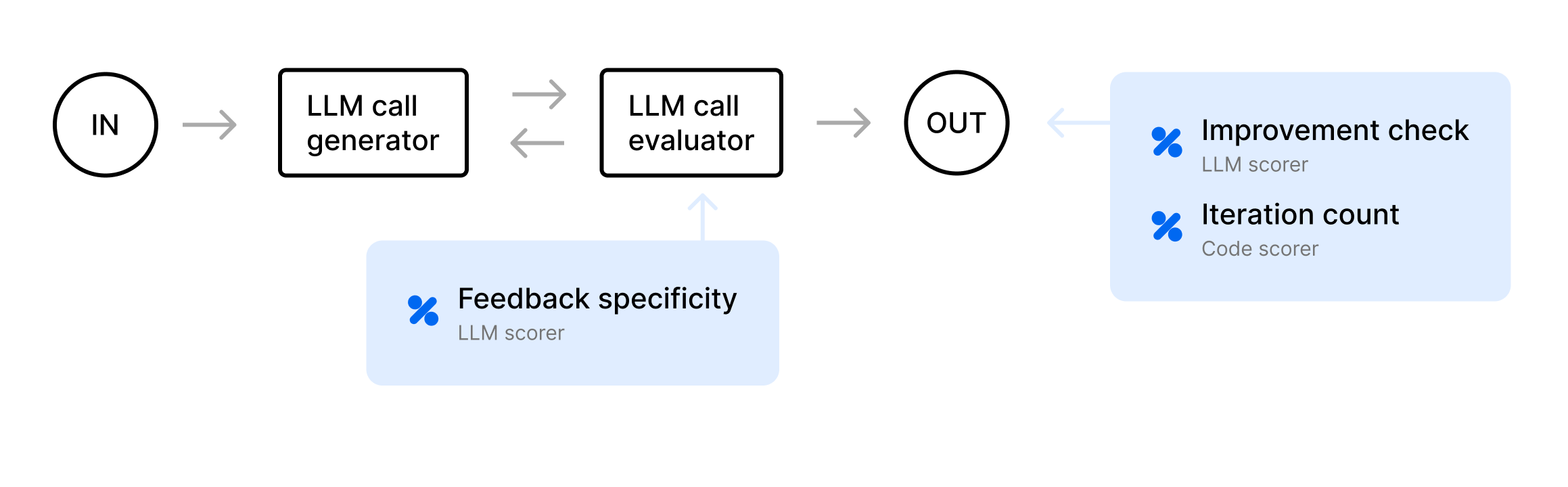
- One LLM (“optimizer”) attempts a solution
- Another LLM (“evaluator”) critiques it and provides feedback
- The optimizer refines the answer, repeating until it meets certain criteria or hits an iteration limit
For example, an agent tries to write a short poem. The evaluator LLM says “Needs more vivid imagery.” The agent modifies it, and so on.
ImprovementCheck- compares the initial draft (stored in metadata) and the final output, deciding if the final is “significantly improved.” If the final text is basically the same as the first, the evaluator’s feedback wasn’t used effectively.
const ImprovementCheck = LLMClassifierFromTemplate({
name: "Improvement Check",
promptTemplate: `
Initial version:
{{metadata.initialDraft}}
Final version:
{{output}}
Is the final version significantly improved? Answer Y or N.
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: false,
});
IterationCount- logs how many times we looped (used iterations). Scores 1 if it’s less than or equal to some max. This makes sure the agent doesn’t iterate forever.
async function IterationCount({
metadata,
}: {
metadata?: {
usedIterations?: number;
maxIteration?: number;
};
}): Promise<number | null> {
// Skip if required metadata fields are missing
if (!metadata?.usedIterations || !metadata?.maxIteration) {
return null;
}
// Score 1 if usedIterations is less than or equal to maxIteration, otherwise 0
return metadata.usedIterations <= metadata.maxIteration ? 1 : 0;
}
FeedbackSpecificity- rates the evaluator’s feedback (stored in metadata) for clarity. For example, is it more than 20 characters, or does it mention specific improvements? If the evaluator always says “Looks good!” the “optimization” loop won’t help.
const FeedbackSpecificity = LLMClassifierFromTemplate({
name: "Feedback Specificity",
promptTemplate: `
Here is the feedback provided by the evaluator:
{{metadata.feedback}}
Rate the feedback on specificity and clarity. Consider the following:
- Is it more than 20 characters?
- Does it suggest specific improvements or point out areas of concern?
- Avoid generic responses like "Looks good!" or "Well done."
Provide a score from 0 to 1 where:
- 1: Feedback is clear, specific, and actionable.
- 0: Feedback is too generic or lacks clarity and actionable suggestions.
Explain your reasoning.
`,
choiceScores: {
"1": 1,
"0": 0,
},
useCoT: true,
});
Fully autonomous agent
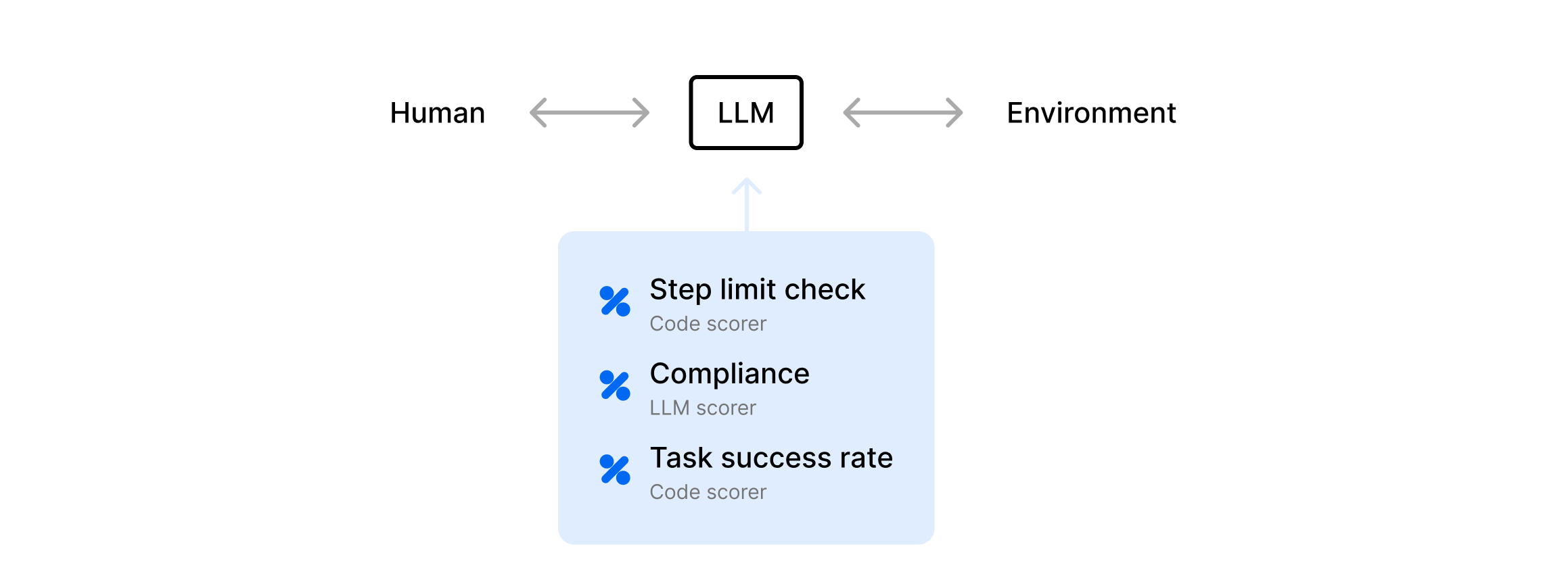
- The agent decides each step on its own, calling tools, asking the user for more info, or finishing the task.
- It can run for many steps or until it hits a maximum iteration/cost guardrail.
For example, consider an agent that books travel. It calls an AirlineAPI tool to find flights, then a PaymentAPI tool to complete the booking. It continues working step-by-step until it completes the task or encounters a guardrail.
Autonomous agents are difficult to evaluate because they can contain any number of the above agentic systems within them. As you choose scorers for your autonomous agents, consider each step the agent takes and what scorers from earlier examples might be useful for that step.
StepLimitCheck- simple scorer to ensure the agent’s step count is less than or equal to 5. Autonomy can lead to runaway loops.
async function StepLimitCheck({
metadata,
}: {
metadata?: {
stepsTaken?: number;
};
}): Promise<number | null> {
// Skip if stepsTaken is not provided in metadata
if (metadata?.stepsTaken === undefined) {
return null;
}
// Score 1 if stepsTaken is <= 5, otherwise 0
return metadata.stepsTaken <= 5 ? 1 : 0;
}
ComplianceCheck- another LLM checks the final log or output for policy violations (harassment, disallowed content, etc.). Fully autonomous agents can easily do the wrong thing without direct guardrails.
const ComplianceCheck = LLMClassifierFromTemplate({
name: "Compliance Check",
promptTemplate: `
Agent's final log/output:
{{output}}
Is this content safe and compliant? Reply "Y" if yes, "N" if no.
`,
choiceScores: {
Y: 1,
N: 0,
},
useCoT: true,
});
TaskSuccessRate- checks whether the agent claims success (like “Booking confirmed”) or ifmetadata.successClaimedis true. At the end, we need to check if the agent actually finished the job.
async function TaskSuccessRate({
output,
metadata,
}: {
output: string;
metadata?: {
successClaimed?: boolean;
};
}): Promise<number> {
// Score 1 if metadata indicates successClaimed is true
if (metadata?.successClaimed) {
return 1;
}
// Score 1 if the output indicates task completion
if (output.toLowerCase().includes("task completed")) {
return 1;
}
// Otherwise, score 0
return 0;
}
Best practices
Ultimately, choosing the right set of scorers will depend on the exact setup of your agentic system. In addition to the specific examples for the types of agents above, here’s some general guidance for how to choose the right evaluation metrics.
Code-based scorers are great for:
- Exact or binary conditions
- Did the system pick the “customer support” route?
- Did it stay under 5 steps?
- Numeric comparisons
- Numeric difference from the expected output
- Structured or factual checks
- Is the final code snippet error-free?
LLM-as-a-judge scorers are best when:
- You need subjective or contextual feedback
- Did the agent output a coherent paragraph?
- Human-like interpretation is needed to decide if the agent responded politely or thoroughly
- You want to check improvement across multiple drafts
Autoevals are useful for:
- Basic correctness (Factuality)
- QA tasks (ClosedQA)
- Similarity checks (EmbeddingSimilarity)
Custom scorers let you:
- Incorporate domain-specific knowledge
- Checking that a generated invoice meets certain business rules
- Evaluate multi-step flows
- Partial checks, iteration loops
- Implement your own specialized logic
- Analyzing a chain-of-thought or verifying references in a research doc
Over time, you can refine or replace scorers as you learn more about the real-world behaviors of your agent at scale.
Next steps
When you’re happy with your scorers, you can deploy them at scale on production logs by configuring online evaluation. Online evaluation runs your scoring functions asynchronously as you upload logs.
If your agentic system is extremely complex, you may want to incorporate human review. This can take the form of incorporating user feedback, or having your product team or subject matter experts manually evaluate your LLM outputs. You can use human review to evaluate/compare experiments, assess the efficacy of your automated scoring methods, and curate log events to use in your evals.