Contributed by Ornella Altunyan on 2025-02-08
When building AI applications that require consistent, structured responses, you have to decide how to implement structured outputs based on the LLM provider you’re using.
Generally, if you’re using a model from OpenAI, you’d just use structured outputs.
If you want to use models from Anthropic, however, you’d need to take a different approach and use their Tool feature, or use prompt engineering to get the desired response.
In the Braintrust Playground, it’s easy to use either AI provider with structured outputs by simply selecting Structured output from the output dropdown menu and defining a JSON schema. If you use the AI proxy, you can also use OpenAI SDKs in your code to speak structured outputs to Anthropic models. Structured outputs work in Braintrust for most LLMs.
In this cookbook, we’ll explore how to use structured outputs and Anthropic models in the playground to classify spam in text messages.
Getting started
Before getting started, make sure you have a Braintrust account and an API key for Anthropic. Make sure to plug the Anthropic key into your Braintrust account’s AI providers configuration. In this cookbook, we’ll be working entirely in the Braintrust UI, so there’s no need for a separate code editor.Setting up the playground
The first thing you’ll need to do is create a new project. Name your project “Spam classifier.” Then, navigate to Evaluations > Playgrounds and create a new playground. In Braintrust, a playground is a tool for exploring, comparing, and evaluating prompts.Importing a dataset
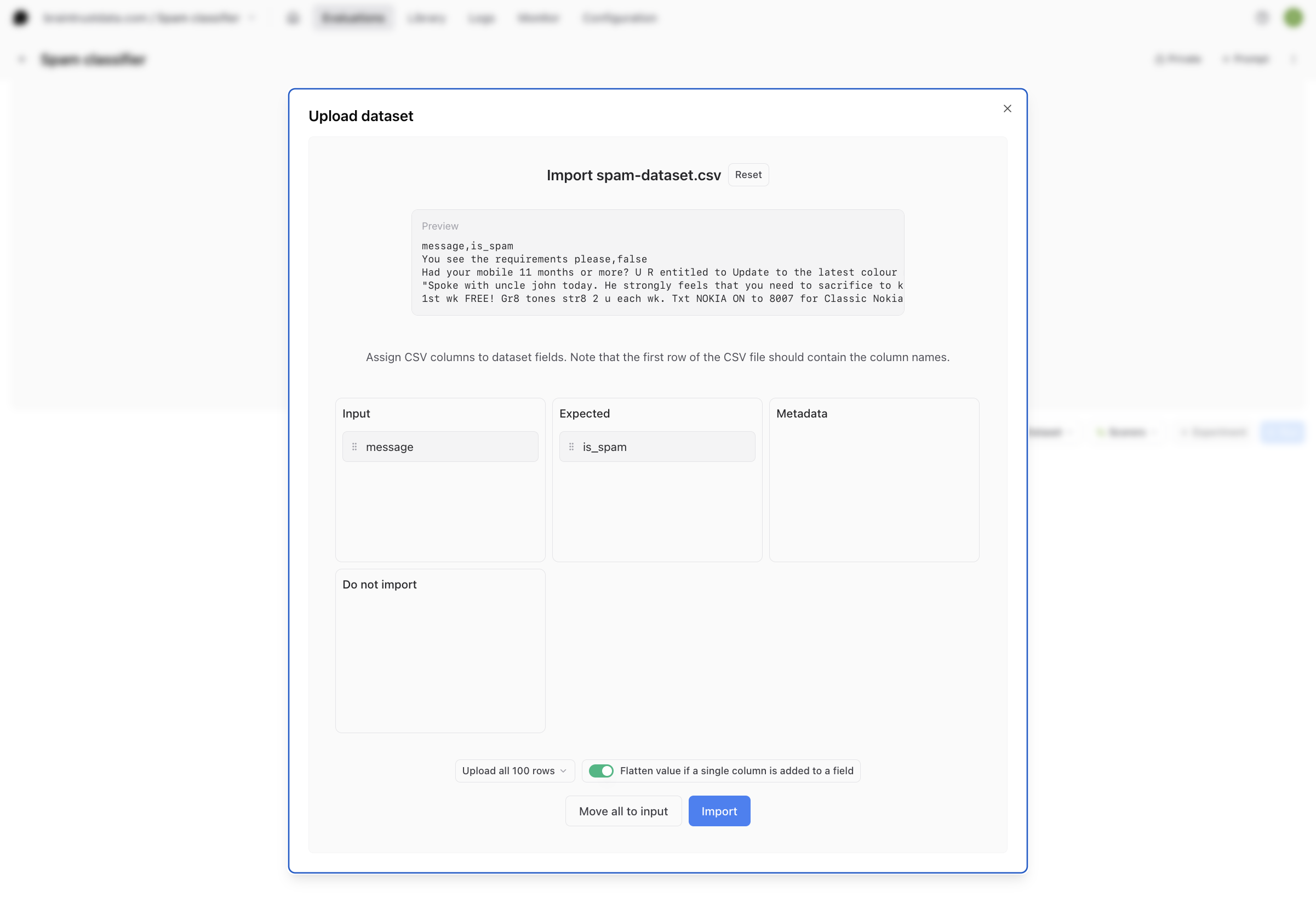
Download the dataset of text messages from GitHub– it is a.csv file with two columns, message and is_spam. Inside your playground, select Dataset, then Upload dataset, and upload the CSV file. Using drag and drop, assign the CSV columns to dataset fields. The input column corresponds to message, and the expected column should be is_spam. Then, select Import.
Writing a prompt
Recall that for this cookbook, we’re going to be using Anthropic models. Choose Claude 3.5 Sonnet Latest or your favorite Anthropic model from the model dropdown. Then, type this for your system prompt: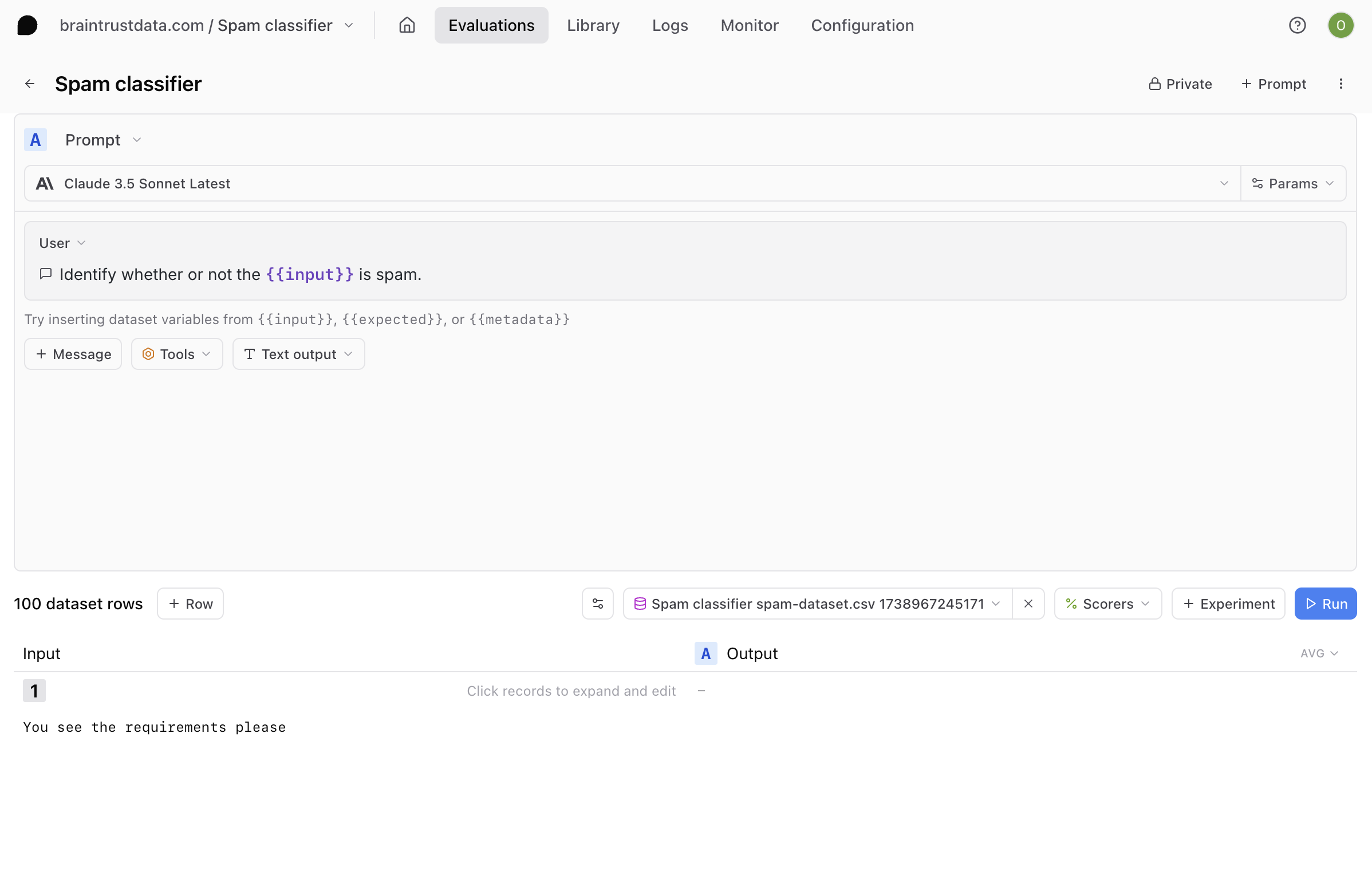
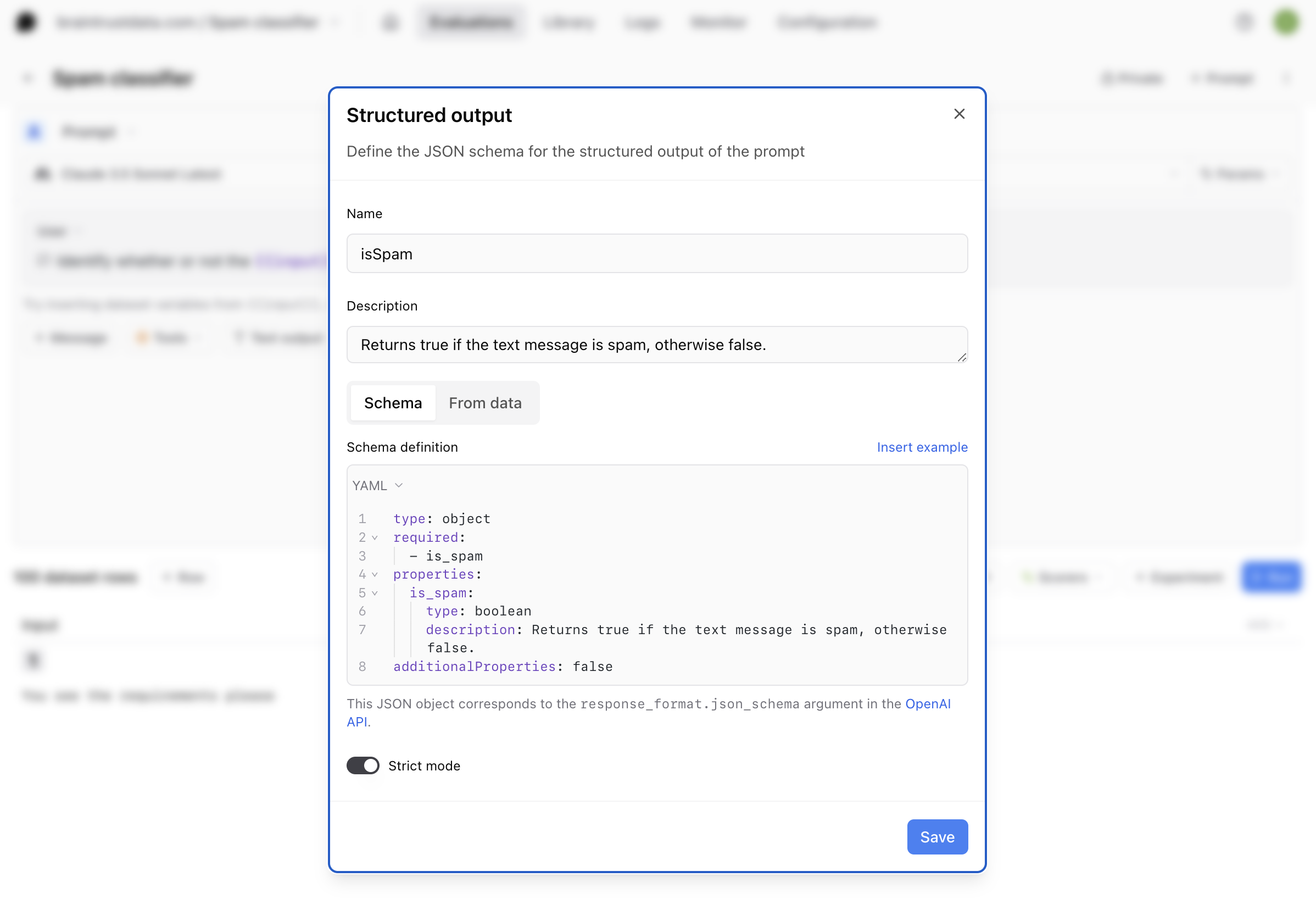
Defining a structured output
Select Structured output from the output dropdown menu and define the JSON schemaisSpam for the structured output of the prompt, using this code for the schema definition:
Running the prompt
Selecting Run will run the LLM call on each input and generate an output. The output of each call will be in the format we created:Running an eval
To close the loop, let’s run an evaluation. To run an eval, you need three things:- Data: a set of examples to test your application on
- Task: the AI function you want to test (any function that takes in an input and returns an output)
- Scores: a set of scoring functions that take an input, output, and optional expected value and compute a score
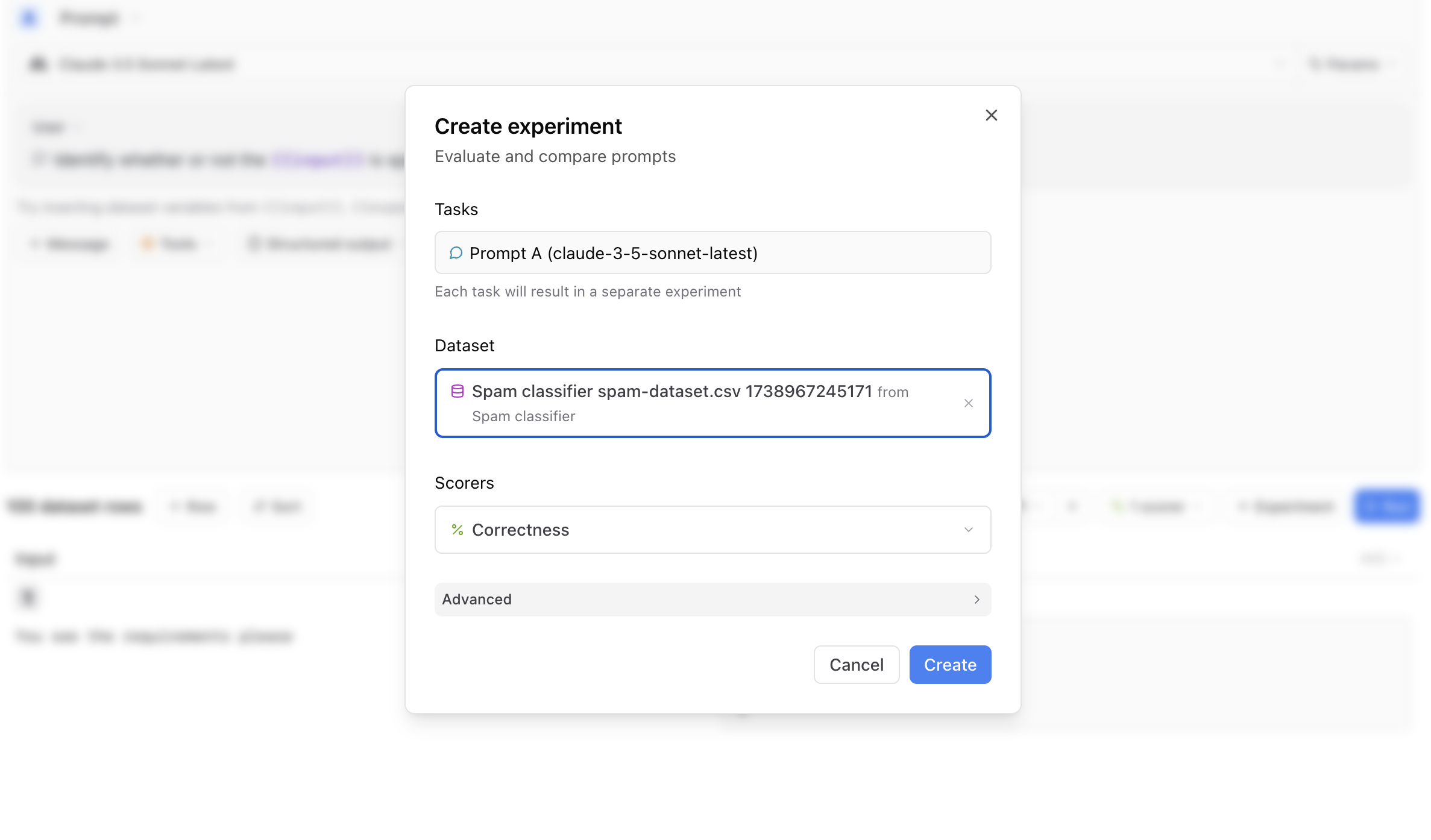
Creating a custom scorer
A scoring function allows you to compare the expected output of a task to the actual output and produce a score between 0 and 1. Inside your playground, select Scorers to choose from several types of scoring functions. For this example, since we have the expected classifications from the dataset, we can create a scoring function that measures whether or not the LLM output matches the expected classification. Select Scorers, then Create custom scorer. We’ll create a custom TypeScript scorer called “Correctness” that compares the value ofoutput.is_spam to the expected classification:
Interpreting your results
Navigate to the Experiments page to view your evaluation.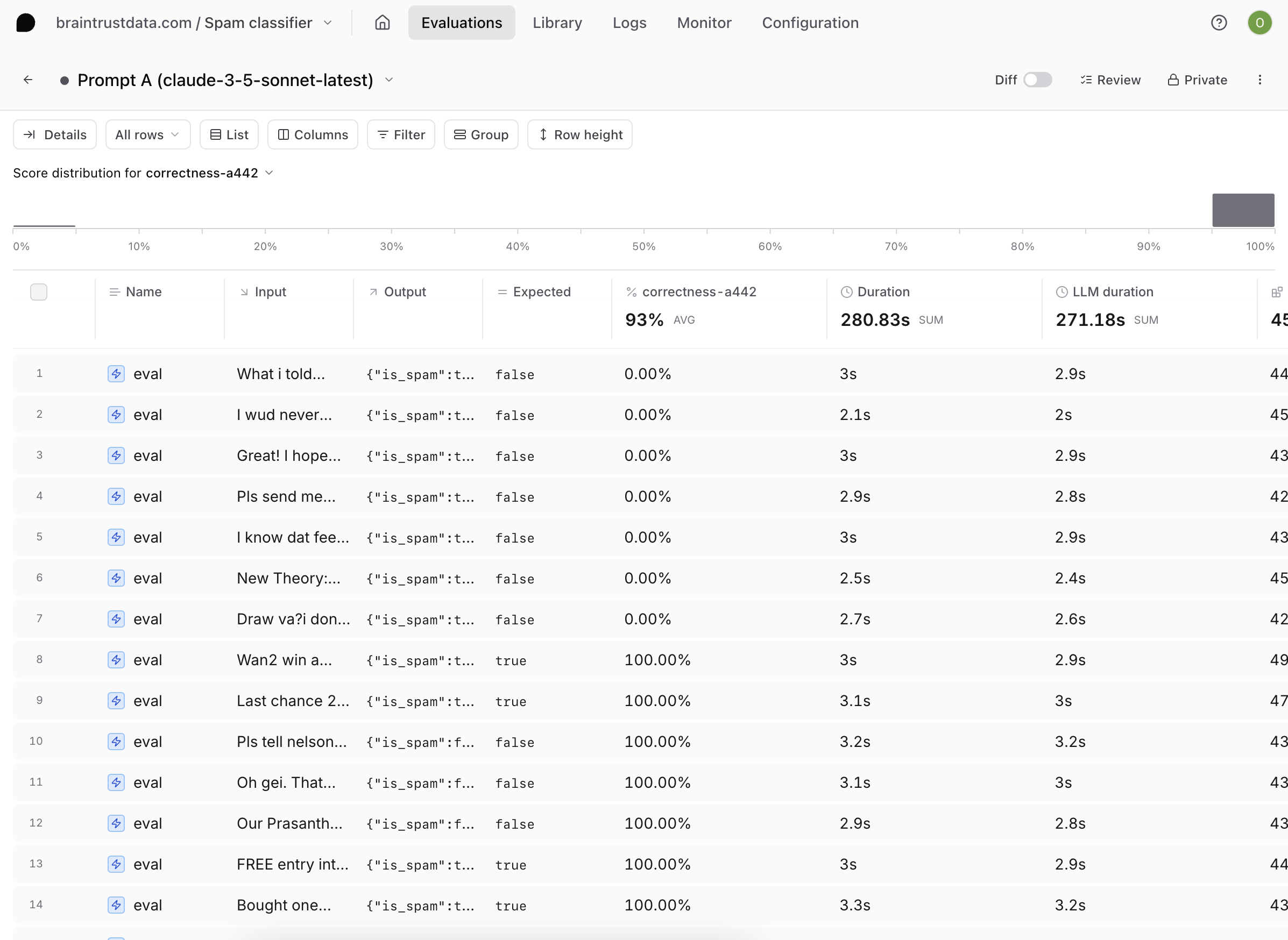
Next steps
In addition to changing your prompt definition and model, you can also:- Add more custom scorers
- Use a larger or more custom dataset
- Write more complex structured output JSON schema