Contributed by Adrian Barbir on 2025-02-13
In this cookbook, we’ll walk through how to evaluate an AI voice agent that classifies short customer support messages by language. In a production application, this might be one component of a customer support agent. Our approach uses an LLM and text-to-speech (TTS) to generate synthetic customer calls, and OpenAI’s GPT-4o audio model to classify the calls. Finally, we’ll use Braintrust to evaluate the performance of the classifier using ExactMatch from our autoevals library.
Getting started
You’ll need a Braintrust account, along with an OpenAI API key. Export yourBRAINTRUST_API_KEY and OPENAI_API_KEY to your environment:
Best practice is to export your API key as an environment variable. However, to make it easier to follow along with this cookbook, you can also hardcode it into the code below.
Generating synthetic support calls
We’ll create a functiongenerate_customer_issue that asks the LLM to produce one-sentence customer service inquiries in multiple languages, along with a fallback if LLM calls fail. Then, we’ll call a TTS endpoint to produce audio from each sentence. We store everything in an array for easy iteration.
Creating evaluation data
We’ll generate multiple snippets for each language, each produced by TTS. If TTS fails, we use a dummy silence clip as a fallback.Task definition and audio attachment
Below is our core task function,task_func, which receives an audio snippet, attaches the raw audio to Braintrust for logging, and prompts an LLM to classify the language. Notice how we create an Attachment object and call current_span().log(input={"audio_attachment": attachment}). This adds the attachment to your log’s trace details, which is helpful if you want to replay or debug your audio data.
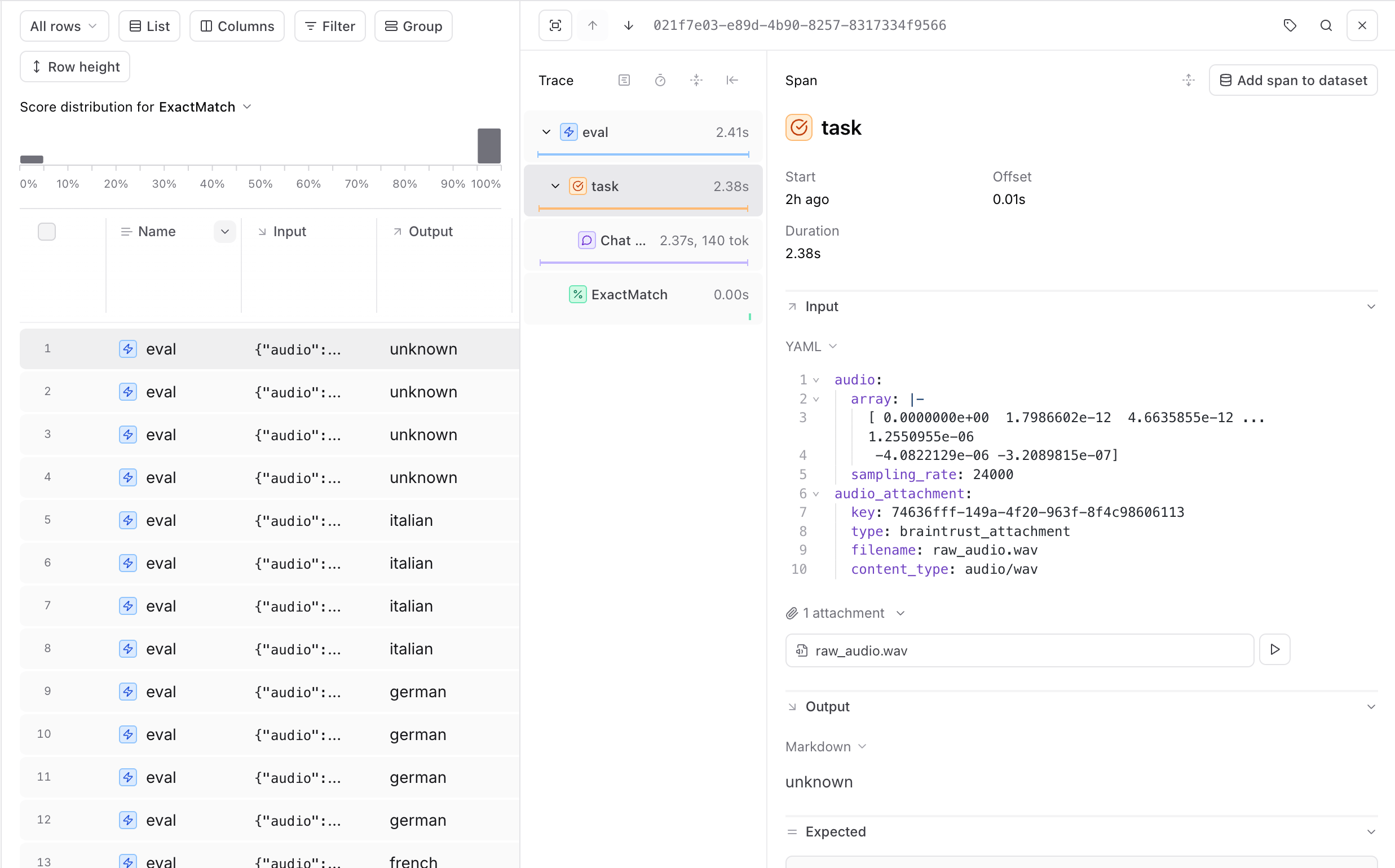
Running the evaluation
To evaluate our voice agent, we runEvalAsync with the ExactMatch scoring function. This will compare the agent’s predicted language to the expected language, returning 1 if they match and 0 otherwise. After you run the code, you’ll be able to analyze the results in the Braintrust UI.
Analyzing results
In the Braintrust UI, you’ll have each audio attachment in its corresponding trace, along with your classification logs and the score. You can refine your prompt or switch to a more advanced model if you notice any incorrect classifications. In our example, we attached metadata to each eval, giving you more granular insights into the classifier’s performance. For example, you can group byexpected_language and see if a particular language fails more often. These sorts of insights allow you to improve your prompting and overall pipeline.
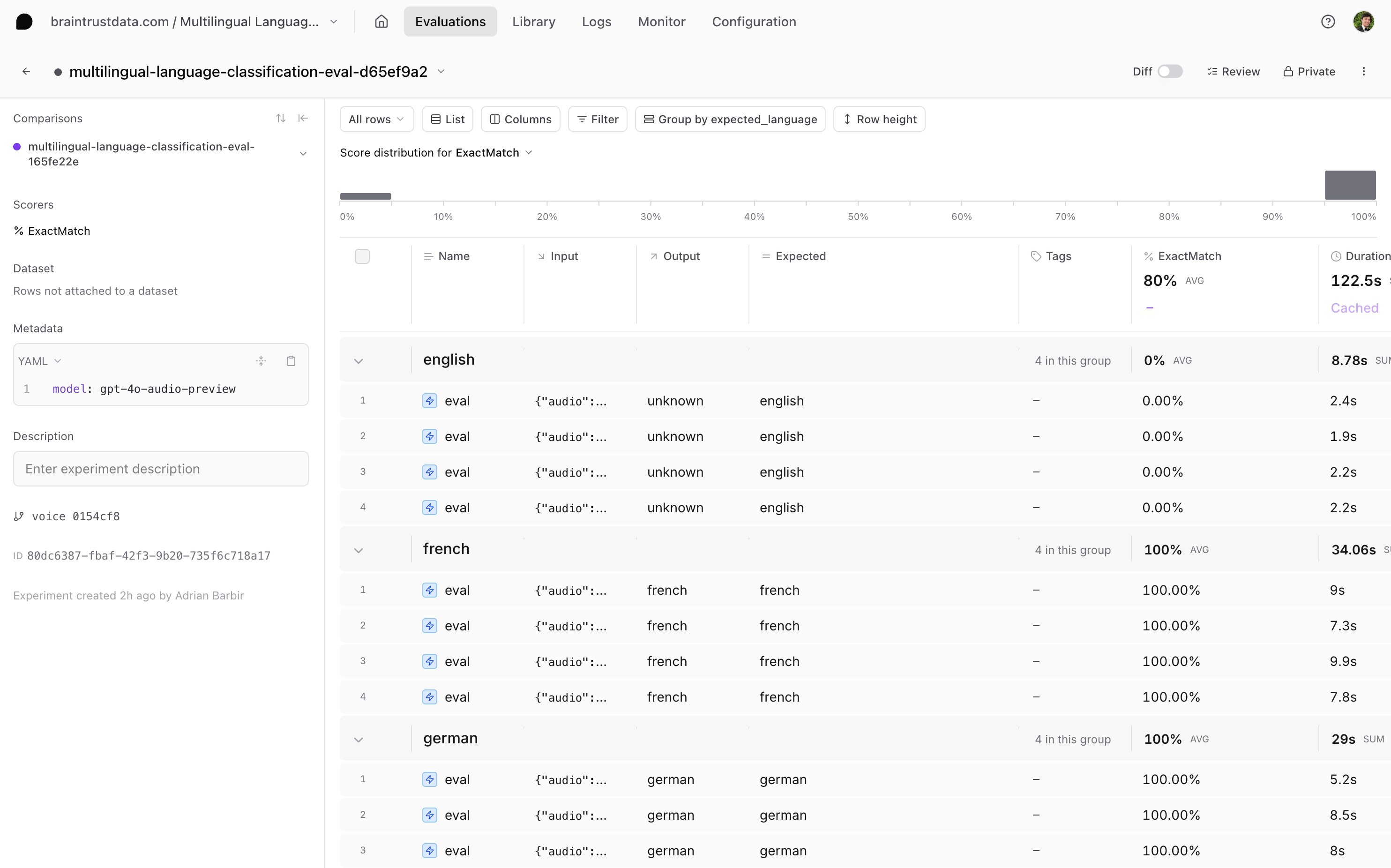
Next steps
As you continue iterating on this voice agent or build more complex AI products, you’ll want to customize Braintrust even more for your use case. You might consider:- Reading our blog on evaluating agents
- Learning to evaluate prompt chaining agents
- Diving deeper into LLM classifiers