Getting started
To follow along, start by installing the required packages:BRAINTRUST_API_KEY as an environment variable:
Exporting your API key is a best practice, but to make it easier to follow along with this cookbook, you can also hardcode it into the code below.
Download Markdown docs from Coda’s Help Desk
Let’s start by downloading the Coda docs and splitting them into their constituent Markdown sections.Use the Braintrust AI Proxy
Let’s initialize the OpenAI client using the Braintrust proxy. The Braintrust AI Proxy provides a single API to access OpenAI and other models. Because the proxy automatically caches and reuses results (whentemperature=0 or the seed parameter is set), we can re-evaluate prompts many times without incurring additional API costs.
Generate question-answer pairs
Before we start evaluating some prompts, let’s use the LLM to generate a bunch of question-answer pairs from the text at hand. We’ll use these QA pairs as ground truth when grading our models later.Evaluate a context-free prompt (no RAG)
Let’s evaluate a simple prompt that poses each question without providing context from the Markdown docs. We’ll evaluate this naive approach using the Factuality prompt from the Braintrust autoevals library.Analyze the evaluation in the UI
The cell above will print a link to a Braintrust experiment. Pause and navigate to the UI to view our baseline eval.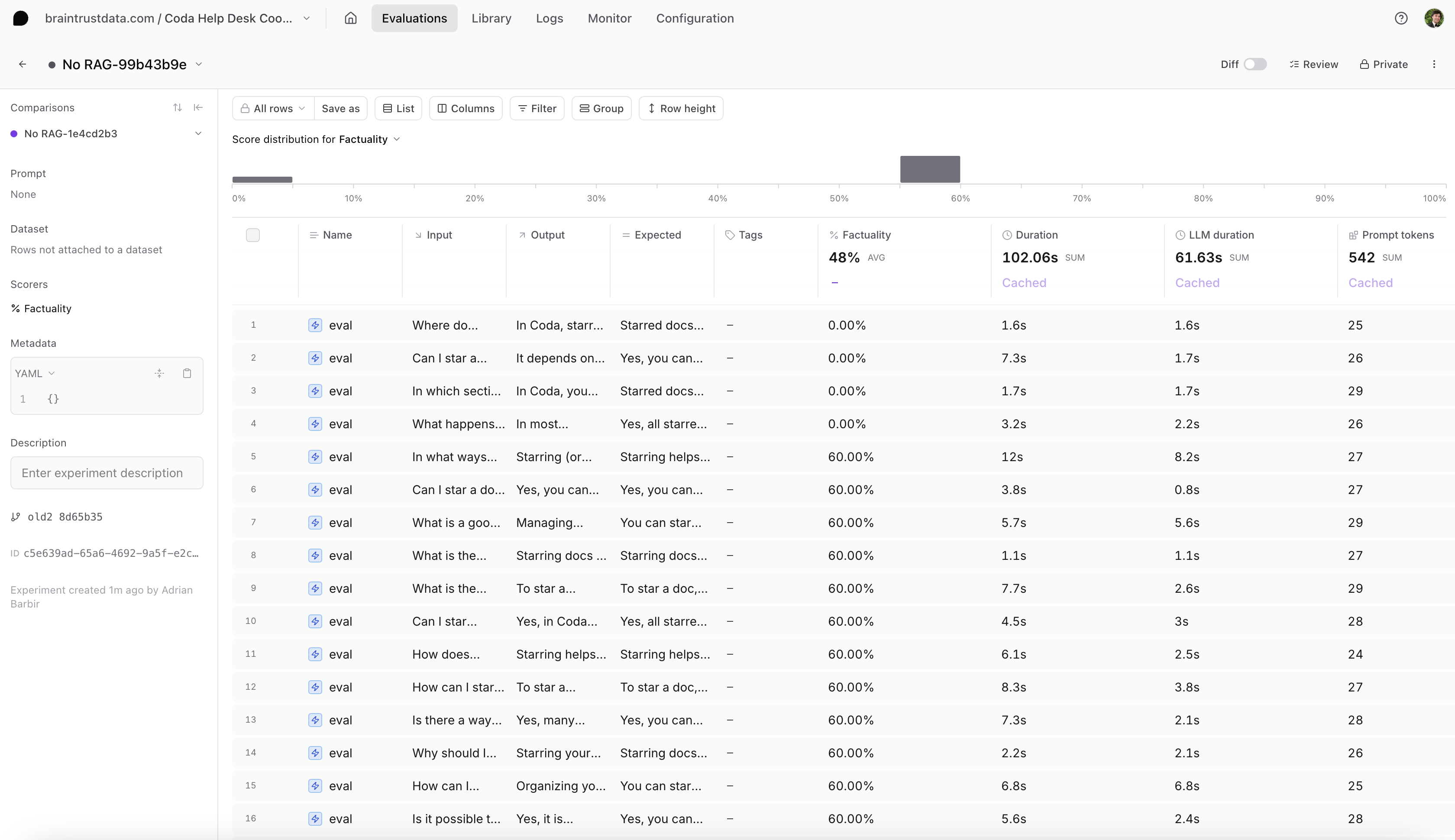
Try using RAG to improve performance
Let’s see if RAG (retrieval-augmented generation) can improve our results on this task. First, we’ll compute embeddings for each Markdown section usingtext-embedding-ada-002 and create an index over the embeddings in LanceDB, a vector database. Then, for any given query, we can convert it to an embedding and efficiently find the most relevant context by searching in embedding space. We’ll then provide the corresponding text as additional context in our prompt.
Use AI to judge relevance of retrieved documents
Let’s retrieve a few more of the best-matching candidates from the vector database than we intend to use, then use the model fromRELEVANCE_MODEL to score the relevance of each candidate to the input query. We’ll use the TOP_K blurbs by relevance score in our QA prompt. Doing this should be a little more intelligent than just using the closest embeddings.
Run the RAG evaluation
Now let’s run our evaluation with RAG:Analyzing the results
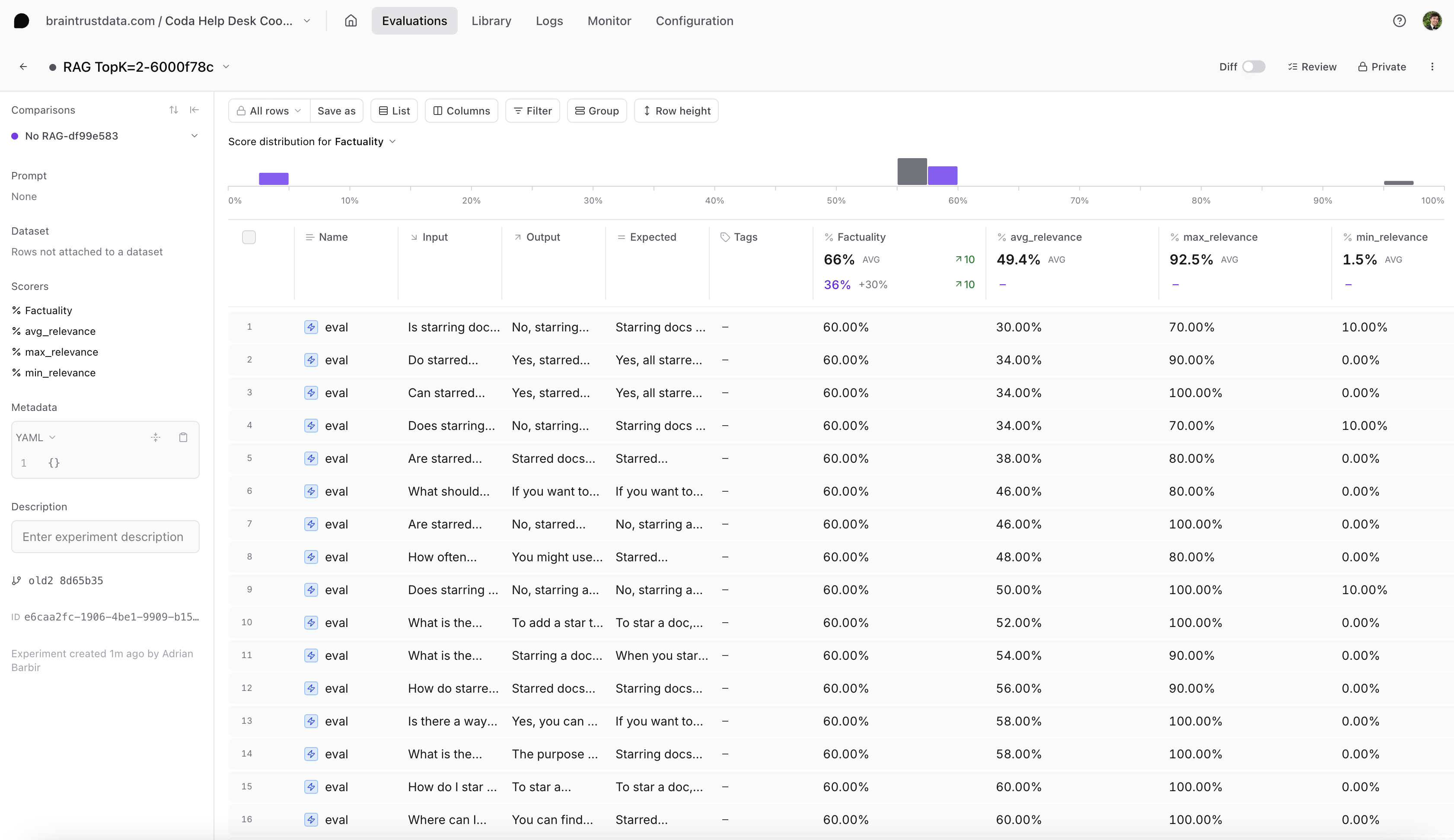
- Braintrust automatically compares the new experiment to your previous one
- You should see an increase in scores with RAG
- You can explore individual examples to see exactly which responses improved
NUM_QA_PAIRS, to run your evaluation on a larger dataset and gain more confidence in your findings.
Next steps
- Learn about using functions to build a RAG agent.
- Compare your evals across different models.
- If RAG is just one part of your agent, learn how to evaluate a prompt chaining agent.