Contributed by Adrian Barbir on 2025-01-17
In this cookbook, we’ll explore how to evaluate an LLM classifier in Braintrust using custom scoring functions that measure precision and recall. We’ll use the GoEmotions dataset, which contains Reddit comments labeled with 28 different emotions. This dataset is interesting since each comment can be labeled with multiple emotions; for example, a single message might express both “excitement” and “anger.”
We’ll build two classifiers-a random baseline and an LLM-based approach using OpenAI’s GPT-4o. By comparing their performance using custom scorers, we’ll demonstrate how to effectively measure and then improve your LLM’s accuracy on complex classification tasks.
Getting started
To get started, you’ll need Braintrust and OpenAI accounts, along with their corresponding API keys. Add yourBRAINTRUST_API_KEY and OPENAI_API_KEY to your environment:
Best practice is to export your API key as an environment variable. However, to make it easier to follow along with this cookbook, you can also hardcode it into the code below.
Type definitions and data models
To ensure that the LLM classifier outputs only emotions predefined by the dataset, we’ll leverage OpenAI’s structured outputs feature by providing a PydanticDynamicModel representing the classification output.
Creating the classifiers
We’ll implement two different approaches to emotion classification:- A random classifier that assigns 1-3 emotions randomly from our predefined list. This random baseline helps us verify that our LLM classifier performs meaningfully better than chance predictions.
- An LLM-based classifier using GPT-4o that uses structured outputs to ensure valid emotion labels.
Implementing evaluation metrics
Because each comment can express multiple emotions, we’re going to use three metrics to assess the performance of our LLM classifier:Precision measures prediction accuracy by calculating the fraction of true positive predictions out of all positive predictions, expressed as (true positives)/(true positives + false positives). If we predict “joy” and “anger” for a comment that only expresses “joy,” we have one true positive and one false positive, so the precision is 0.5. Higher precision means fewer false positives.
Recall measures the fraction of actual emotions that were correctly identified, expressed as (true positives)/(true positives + false negatives). If a comment expresses “sadness” and “fear,” but we only catch “sadness,” we have one true positive and one false negative, so the recall is 0.5. Higher recall means fewer missed emotions.
F1 Score combines precision and recall into a single metric since improving one can hurt the other. It helps balance being too strict (high precision, low recall) and too lenient (high recall, low precision).
Running evaluations
Finally, let’s set up our evaluation pipeline using Braintrust:Analyzing the results
Once you run the evaluations, you’ll see the results in your Braintrust dashboard. The LLM classifier should significantly outperform the random baseline across all metrics.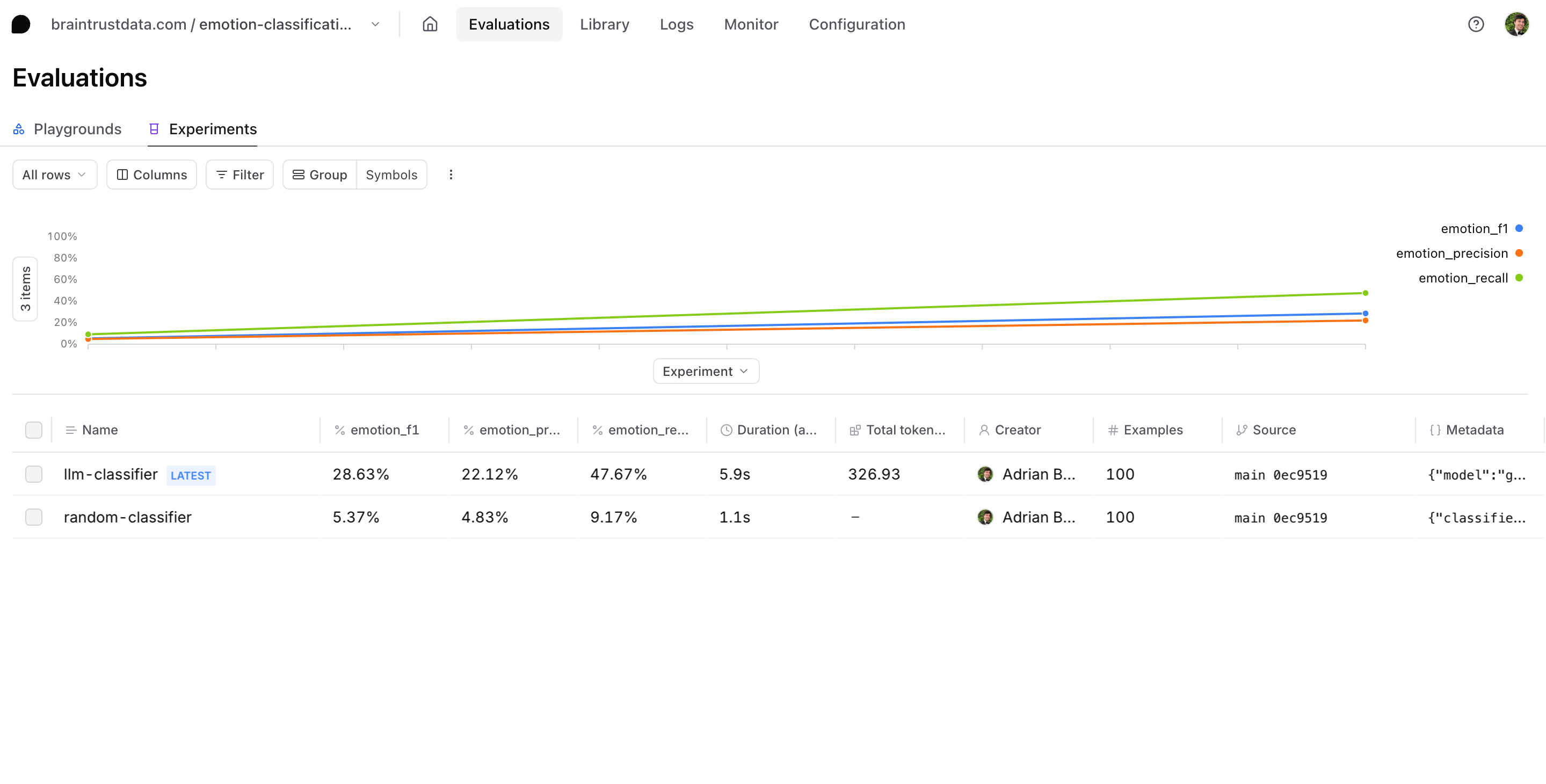
- Compare precision and recall scores between our runs
- Look at specific examples where the LLM fails
- Analyze cases where multiple emotions are present
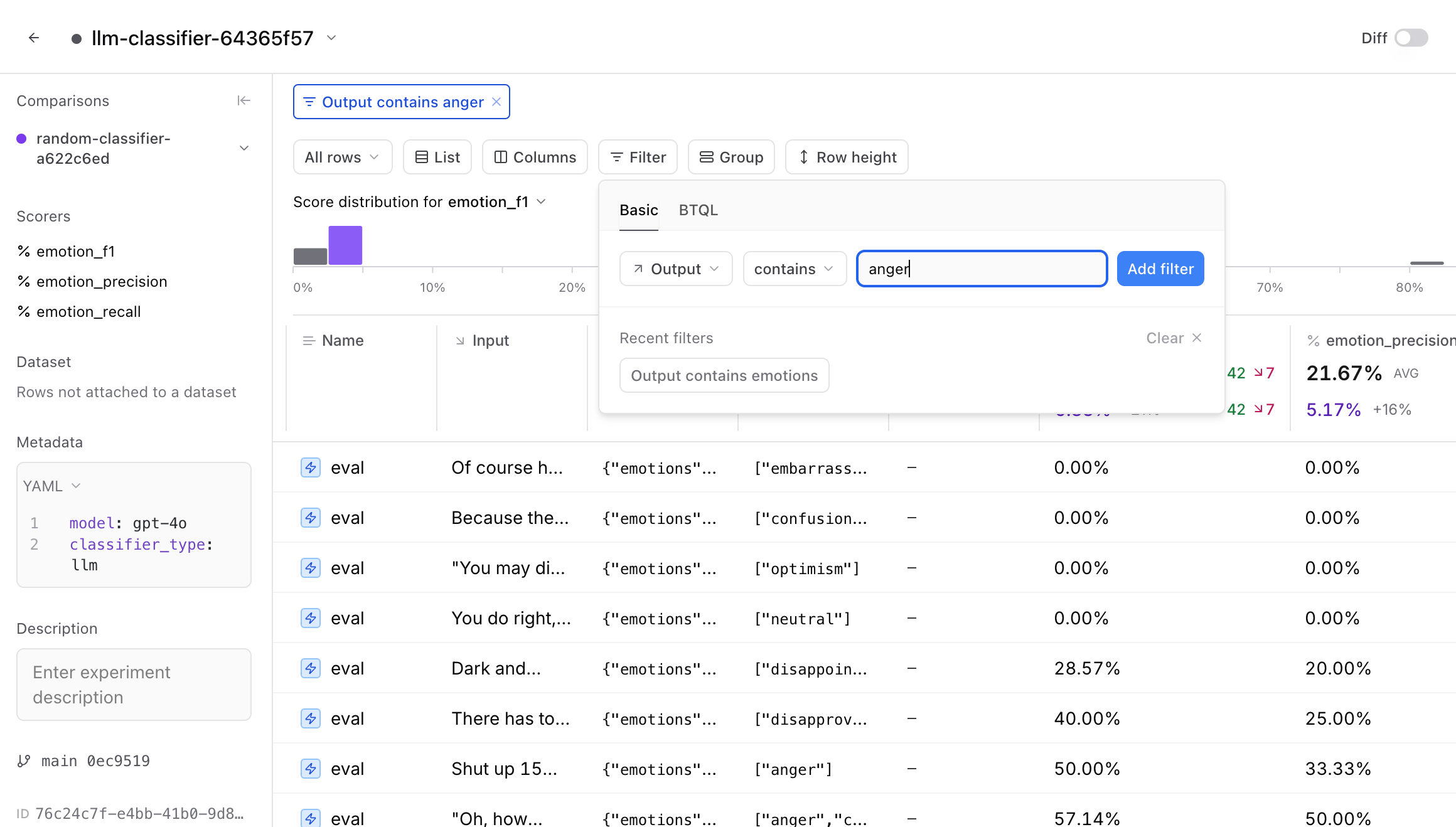
Next steps
There are several ways to improve this emotion classifier, including:- Experimenting with different prompts and instructions, or even a series of prompts.
- Adding a
rationaleto the output for each emotion to help us identify the root cause of the classifier’s failures and improve the prompts accordingly. - Trying other models like xAI’s Grok 2 or OpenAI’s o1. To learn more about comparing evals across multiple AI models, check out this cookbook.
- Adding more sophisticated scoring functions or LLM-based scoring functions to evaluate something like “anger” recall.