Contributed by Adrian Barbir on 2025-02-18
Large language models have gotten extremely good at interpreting text, but understanding and answering questions about video content is a newer area of focus. It’s especially difficult for domain-specific tasks, like sports broadcasts or educational videos, where specific visual details can completely change the answer.
In this cookbook, we’ll explore how to evaluate an LLM-based video question-answering (Video QA) system using the MMVU dataset. The MMVU dataset includes multi-disciplinary videos paired with questions and ground-truth answers, spanning many different topics.
By the end, you’ll have a repeatable workflow for quantitatively evaluating video QA performance, which you can adapt to different datasets or use cases.
Getting started
To follow along, start by installing the required packages:BRAINTRUST_API_KEY as an environment variable:
Exporting your API key is a best practice, but to make it easier to follow along with this cookbook, you can also hardcode it into the code below.
Extracting frames as base64
To give the LLM visual context, we’ll extract up toNUM_FRAMES frames from each video, resize them to TARGET_DIMENSIONS, and encode each frame as a base64 string. This lets us include key snapshots of the video in the prompt:
Downloading or reading raw video data
Storing the raw video file as an attachment in Braintrust can simplify debugging by allowing you to easily reference the original source. The helper functionget_video_data retrieves a video file either from a local path or URL:
Loading the data
We’ll work with the first 20 samples from the MMVU validation split. Each sample contains a video, a question, and an expected answer. We’ll convert the video frames to base64, attach the raw video bytes, and include the question-answer pair: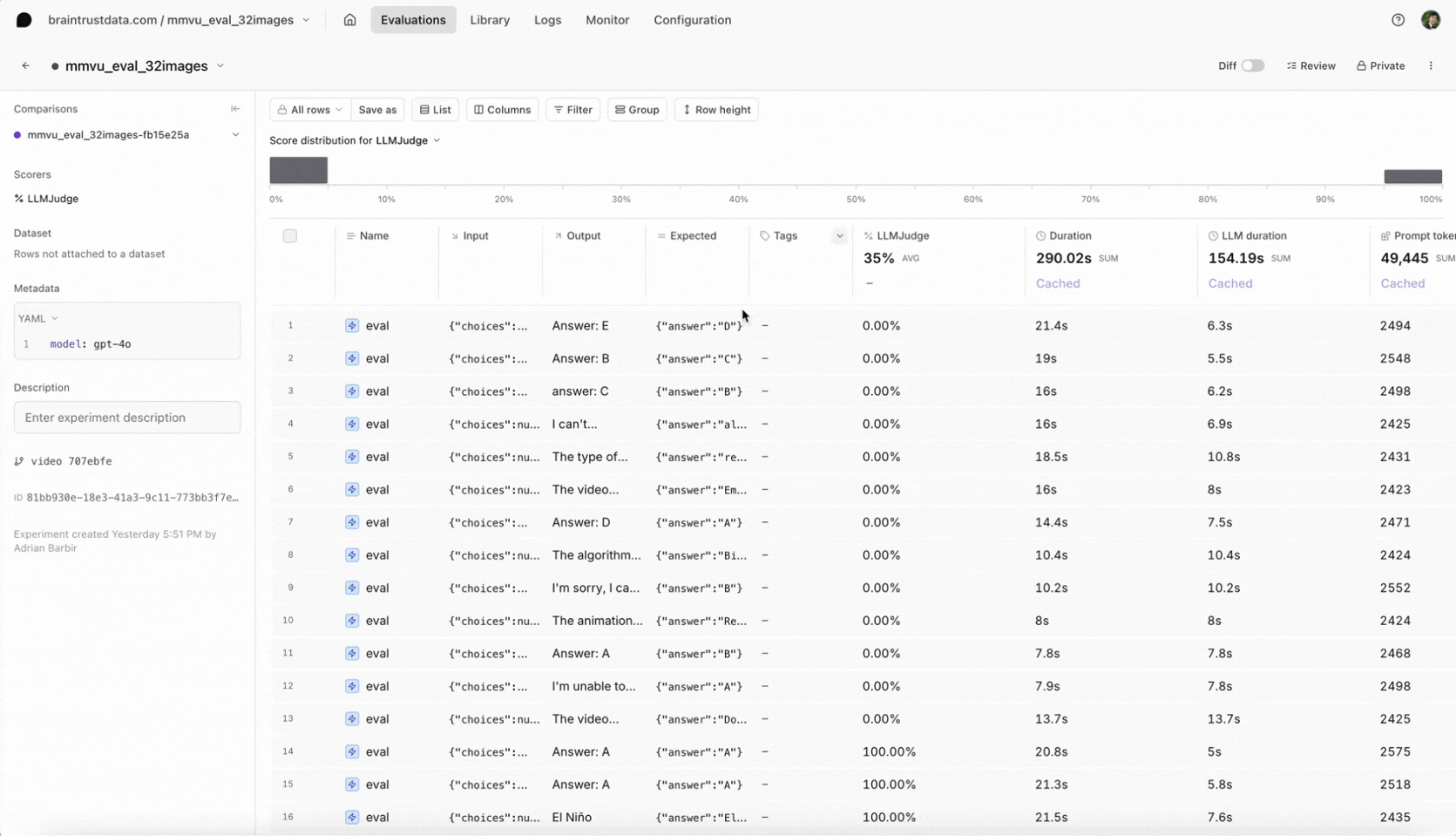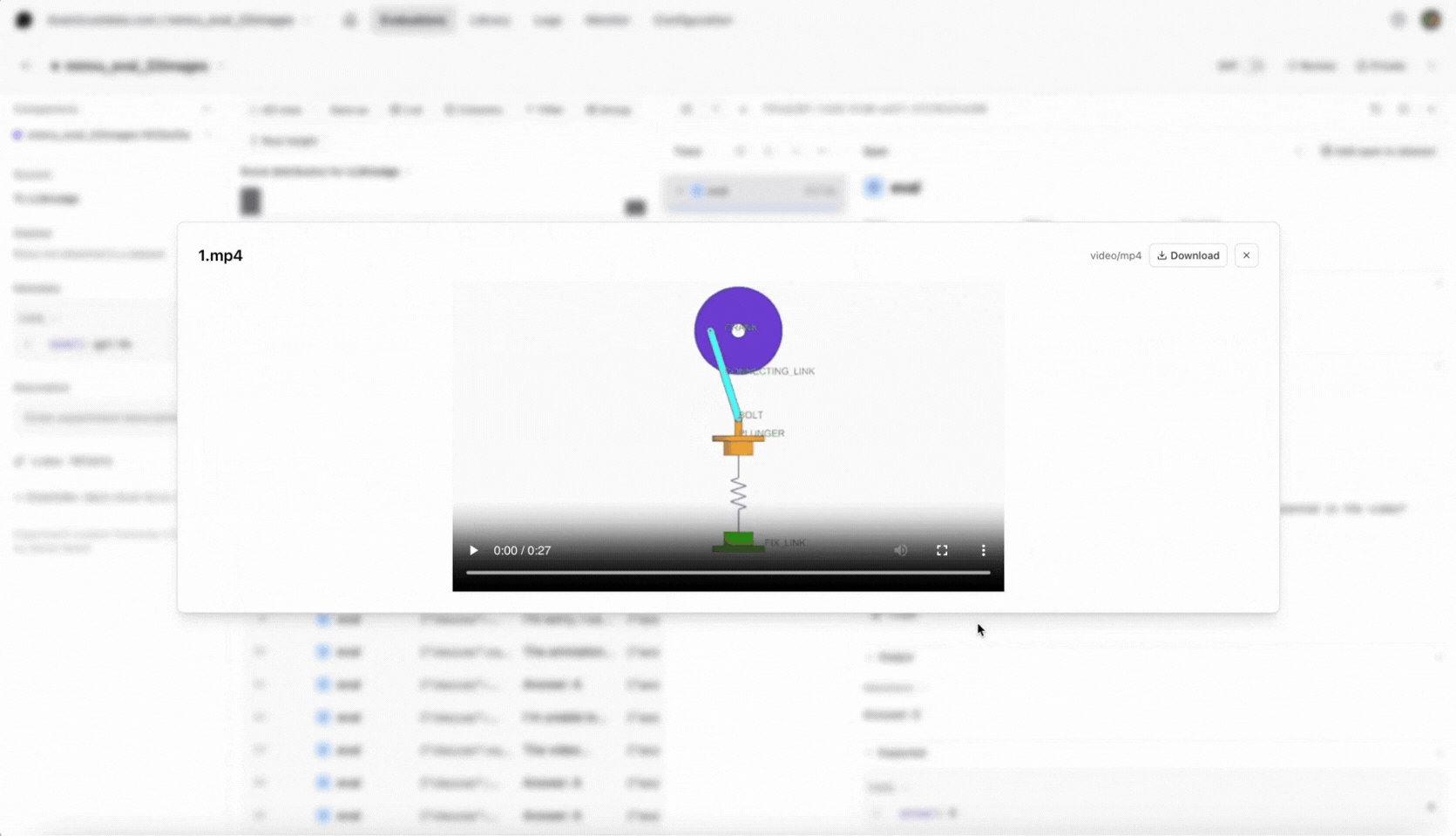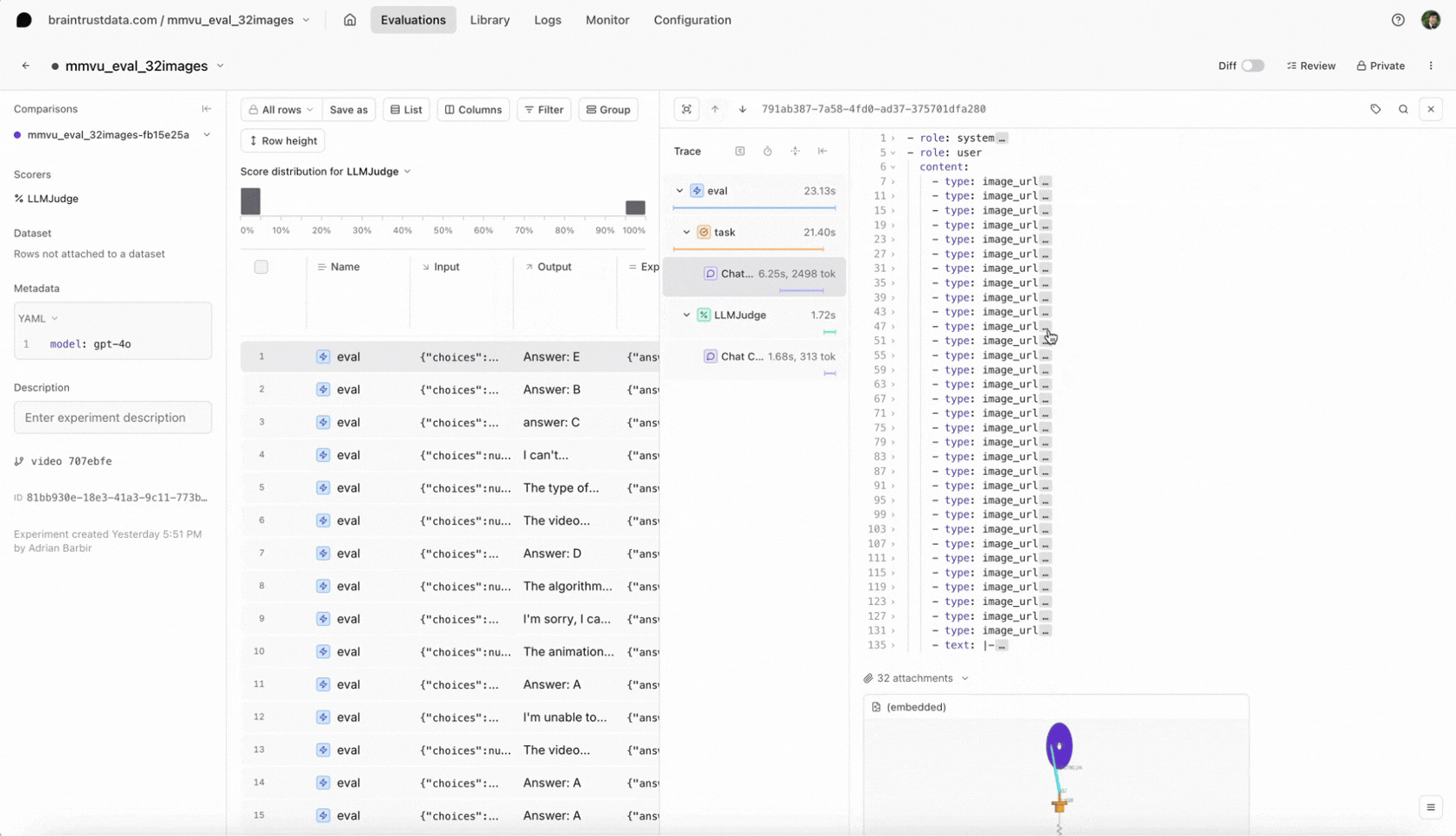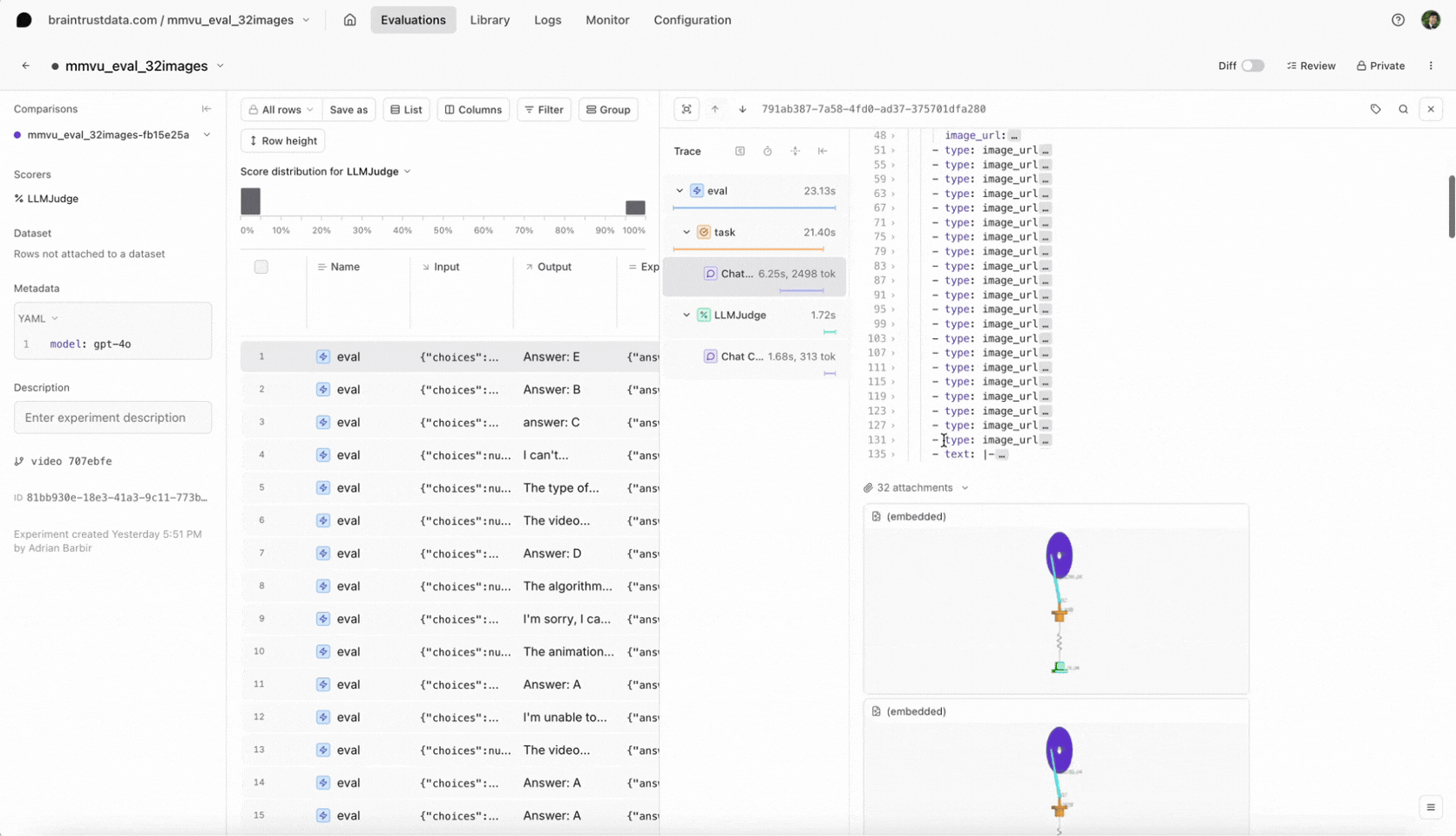
Prompting the LLM
Next, we’ll define avideo_qa function to prompt the LLM for answers. It constructs a prompt with the base64-encoded frames, the question, and, for multiple-choice questions, the available options:
Evaluating the model’s answers
To evaluate the model’s answers, we’ll define a function calledevaluator that uses the LLMClassifier from the autoevals library as a starting point. This scorer compares the model’s output with the expected answer, assigning 1 if they match and 0 otherwise.
Running the evaluation
Now that we have the three required components (a dataset, task, and prompt), we can run the eval. It loads data usingload_data_subset, uses video_qa to get answers from the LLM, and scores each response with evaluator:
Analyzing results
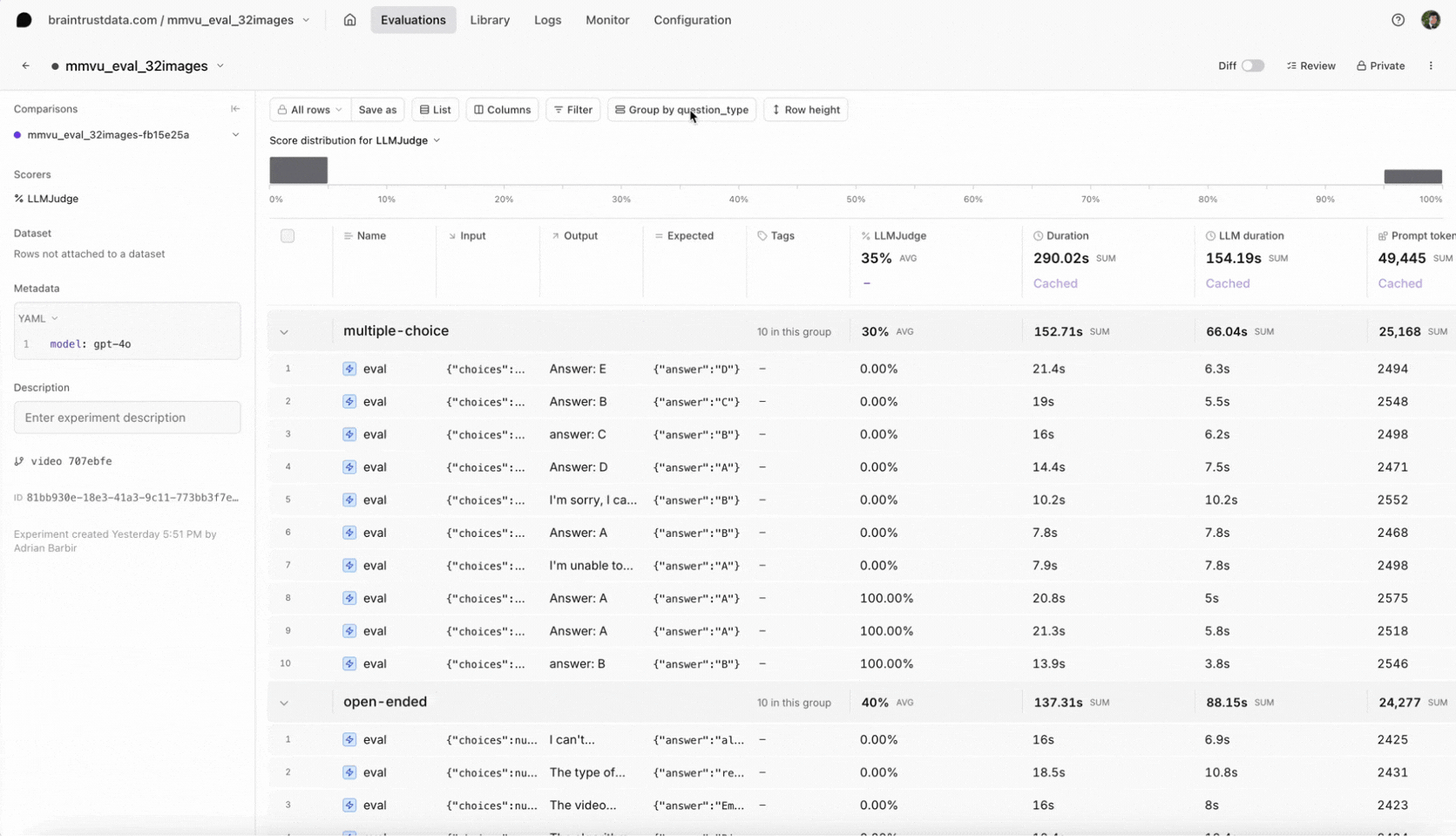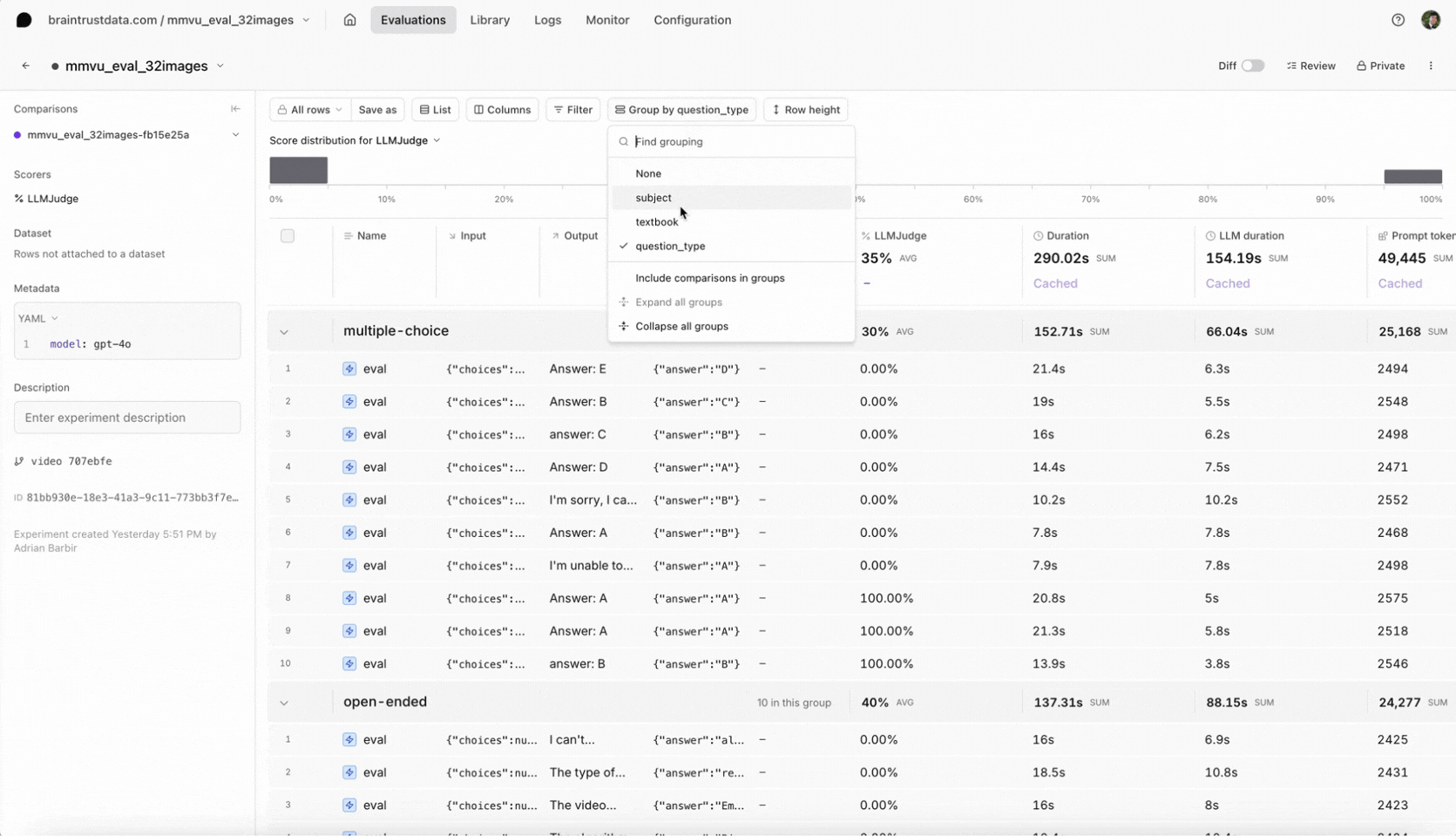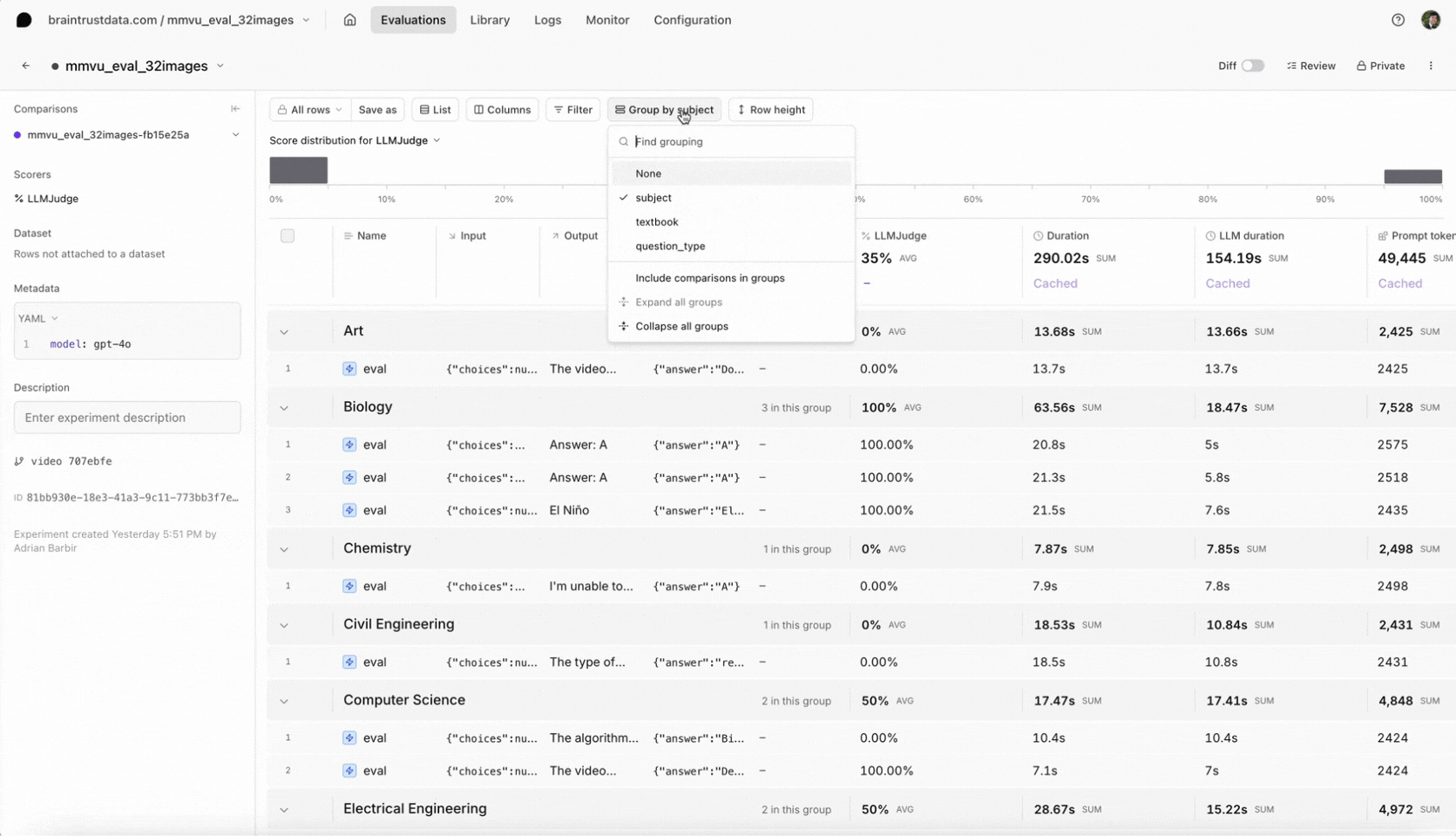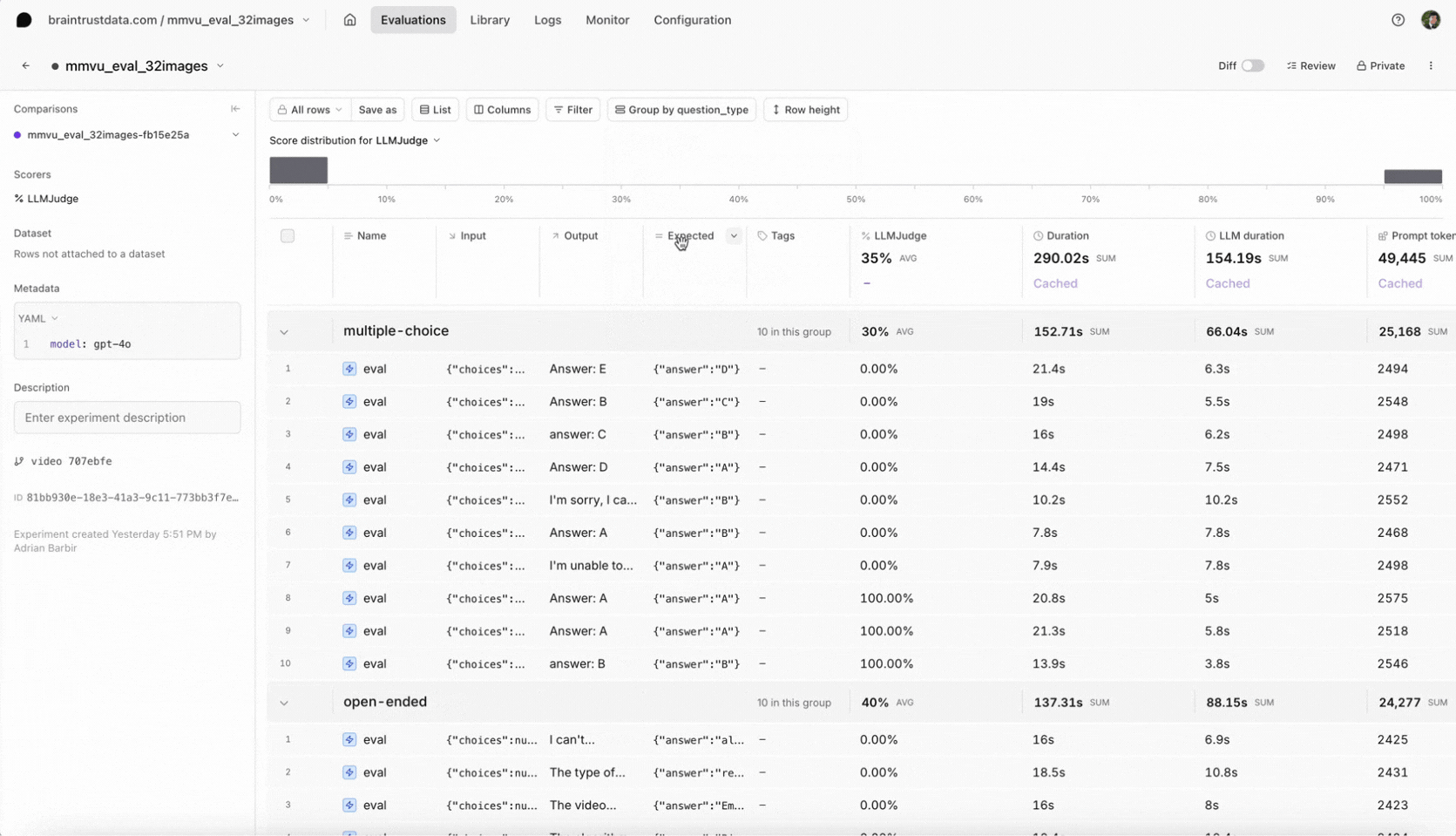
After running the evaluation, head over to Evaluations in the Braintrust UI to see your results. Select your most recent experiment to review the video frames included in the prompt, the model’s answer for each sample, and the scoring by our LLM-based judge. We also attached metadata likesubject and question_type, which you can use to filter in the Braintrust UI. This makes it easy to see whether the model underperforms on a certain type of question or domain. If you discover specific weaknesses, consider refining your prompt with more context or switching models.
Next steps
- Learn more about the MMVU dataset
- Add custom scorers to get more granular feedback (like partial credit, or domain-specific checks)
- Check out our prompt chaining agents cookbook if you’re building complex AI systems where video classification is just one component