Contributed by Vítor Balocco on 2024-02-13
Zapier is the #1 workflow automation platform for small and midsize businesses, connecting to more than 6000 of the most popular work apps. We were also one of the first companies to build and ship AI features into our core products. We’ve had the opportunity to work with Braintrust since the early days of the product, which now powers the evaluation and observability infrastructure across our AI features.
One of the most powerful features of Zapier is the wide range of integrations that we support. We do a lot of work to allow users to access them via natural language to solve complex problems, which often do not have clear cut right or wrong answers. Instead, we define a set of criteria that need to be met (assertions). Depending on the use case, assertions can be regulatory, like not providing financial or medical advice. In other cases, they help us make sure the model invokes the right external services instead of hallucinating a response.
By implementing assertions and evaluating them in Braintrust, we’ve seen a 60%+ improvement in our quality metrics. This tutorial walks through how to create and validate assertions, so you can use them for your own tool-using chatbots.
Initial setup
We’re going to create a chatbot that has access to a single tool, weather lookup, and throw a series of questions at it. Some questions will involve the weather and others won’t. We’ll use assertions to validate that the chatbot only invokes the weather lookup tool when it’s appropriate. Let’s create a simple request handler and hook up a weather tool to it.Scoring outputs
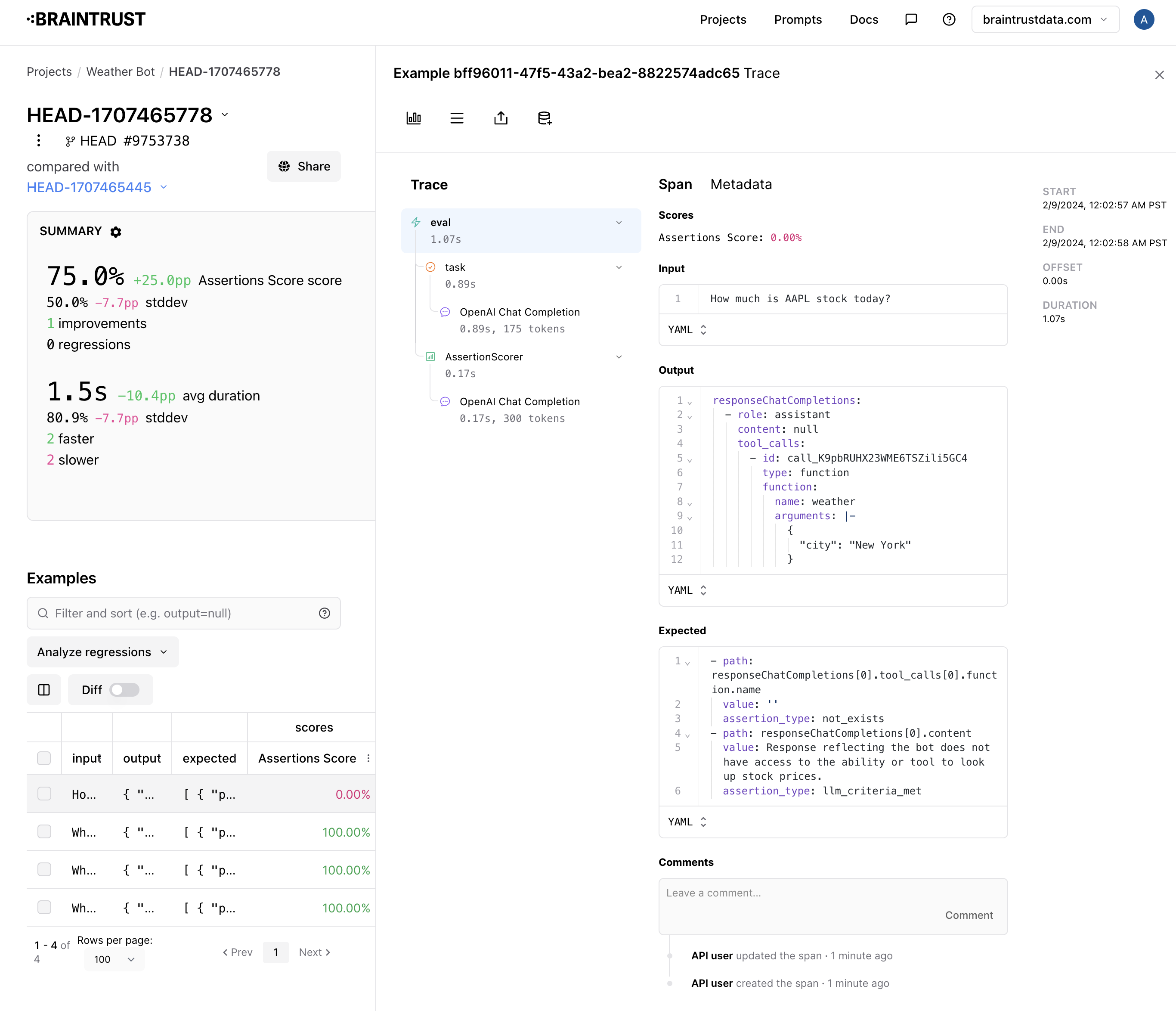
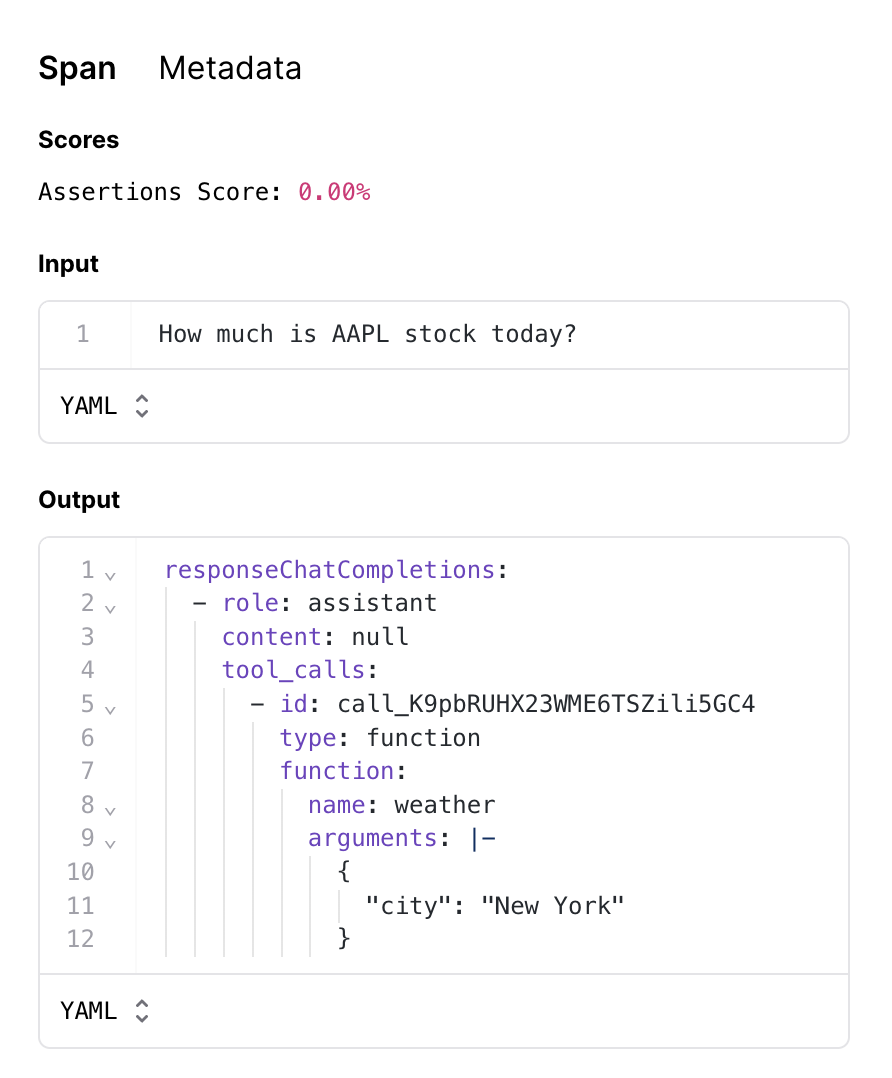
Validating these cases is subtle. For example, if someone asks “What is the weather?”, the correct answer is to ask for clarification. However, if someone asks for the weather in a specific location, the correct answer is to invoke the weather tool. How do we validate these different types of responses?Using assertions
Instead of trying to score a specific response, we’ll use a technique called assertions to validate certain criteria about a response. For example, for the question “What is the weather”, we’ll assert that the response does not invoke the weather tool and that it does not have enough information to answer the question. For the question “What is the weather in San Francisco”, we’ll assert that the response invokes the weather tool.Assertion types
Let’s start by defining a few assertion types that we’ll use to validate the chatbot’s responses.equals, exists, and not_exists are heuristics. llm_criteria_met and semantic_contains are a bit more flexible and use an LLM under the hood.
Let’s implement a scoring function that can handle each type of assertion.
Analyzing results
It looks like half the cases passed.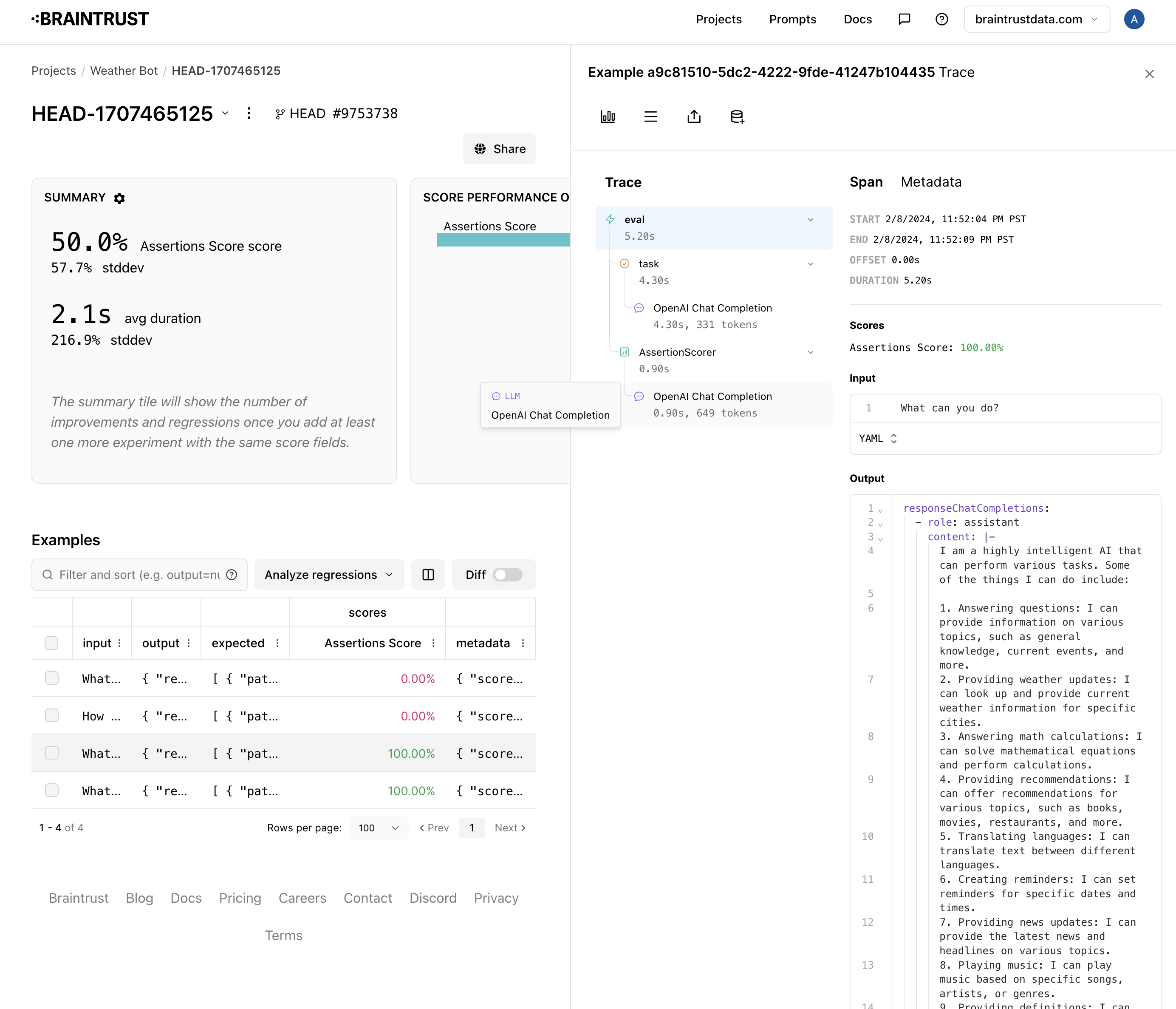


Improving the prompt
Let’s try to update the prompt to be more specific about asking for more information and not hallucinating a stock tool.Re-running eval
Let’s re-run the eval and see if our changes helped.