Contributed by Mengying Li on 2025-12-08
Lovable is a no-code platform that helps non-technical builders create real applications with AI features. After building your app with Lovable, the next step is connecting it to Braintrust so you can see what the AI is doing and iterate confidently. This cookbook guides you through adding Braintrust observability and evaluations to your Lovable app, which runs on Supabase Edge Functions with Deno.
By the end of this cookbook, you’ll learn how to:
- Add Braintrust logging to a Lovable app running on Supabase Edge + Deno
- Configure the Braintrust SDK to send traces for observability
- Run evals to inspect AI behavior including prompts, tool calls, and responses
- Set up remote evals to test changes in your Lovable AI features before deploying
Getting started
To get started, make sure you have:- A Lovable account with an existing app
- A Braintrust account and API key
- Access to your Lovable app’s Edge Functions
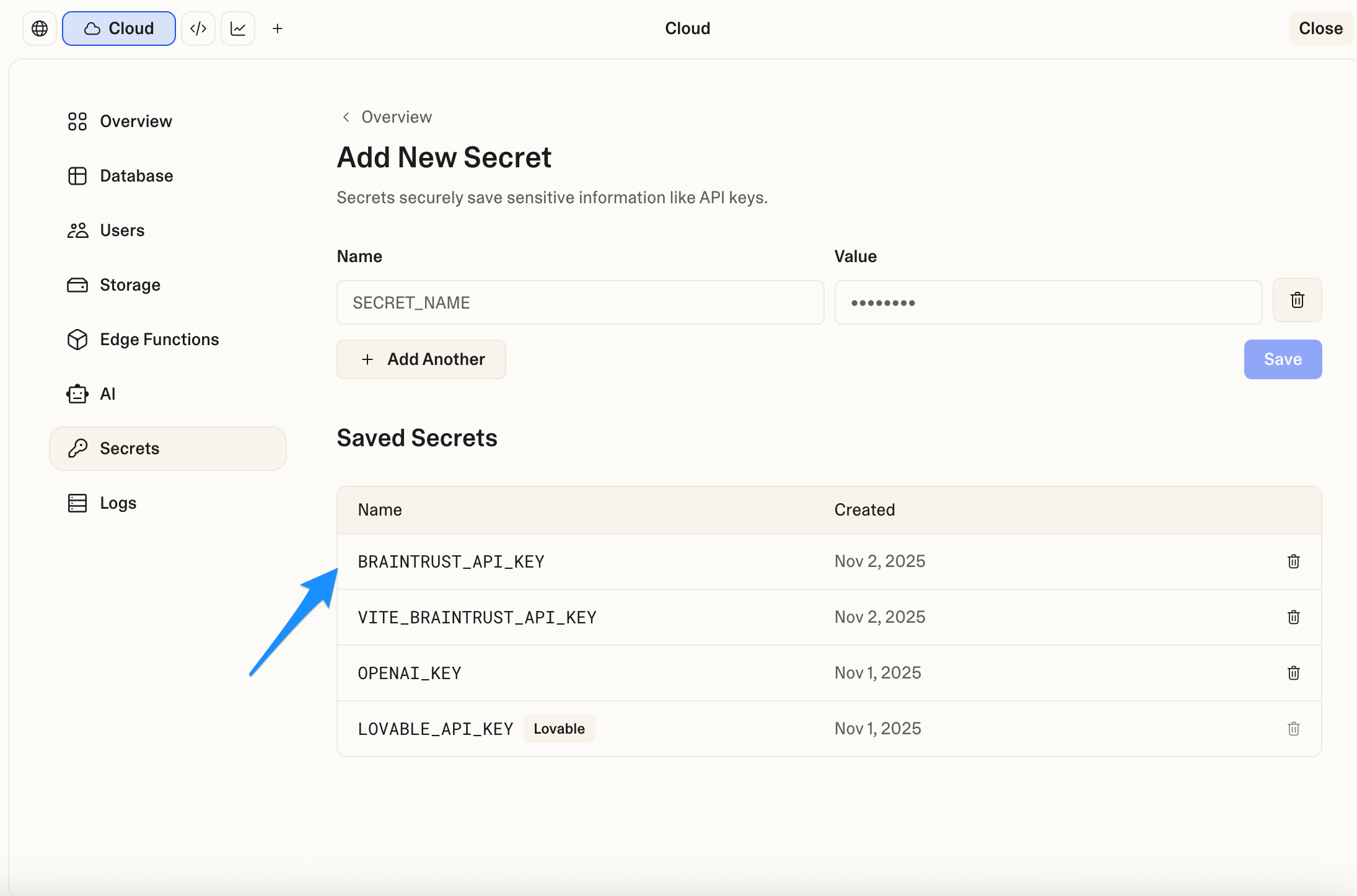
Add your API key to Lovable
From your Lovable chat interface:- Select the cloud icon to access secrets management
- Add a new secret named
BRAINTRUST_API_KEY - Paste your Braintrust API key as the value
- Save the secret
Configure logging in your Edge Function
Ask Lovable to configure Braintrust logging by pasting this prompt into the Lovable chat:View logs
After implementing the logging, run your AI feature end-to-end. Start with text-only if you prefer, and you can add image flows later.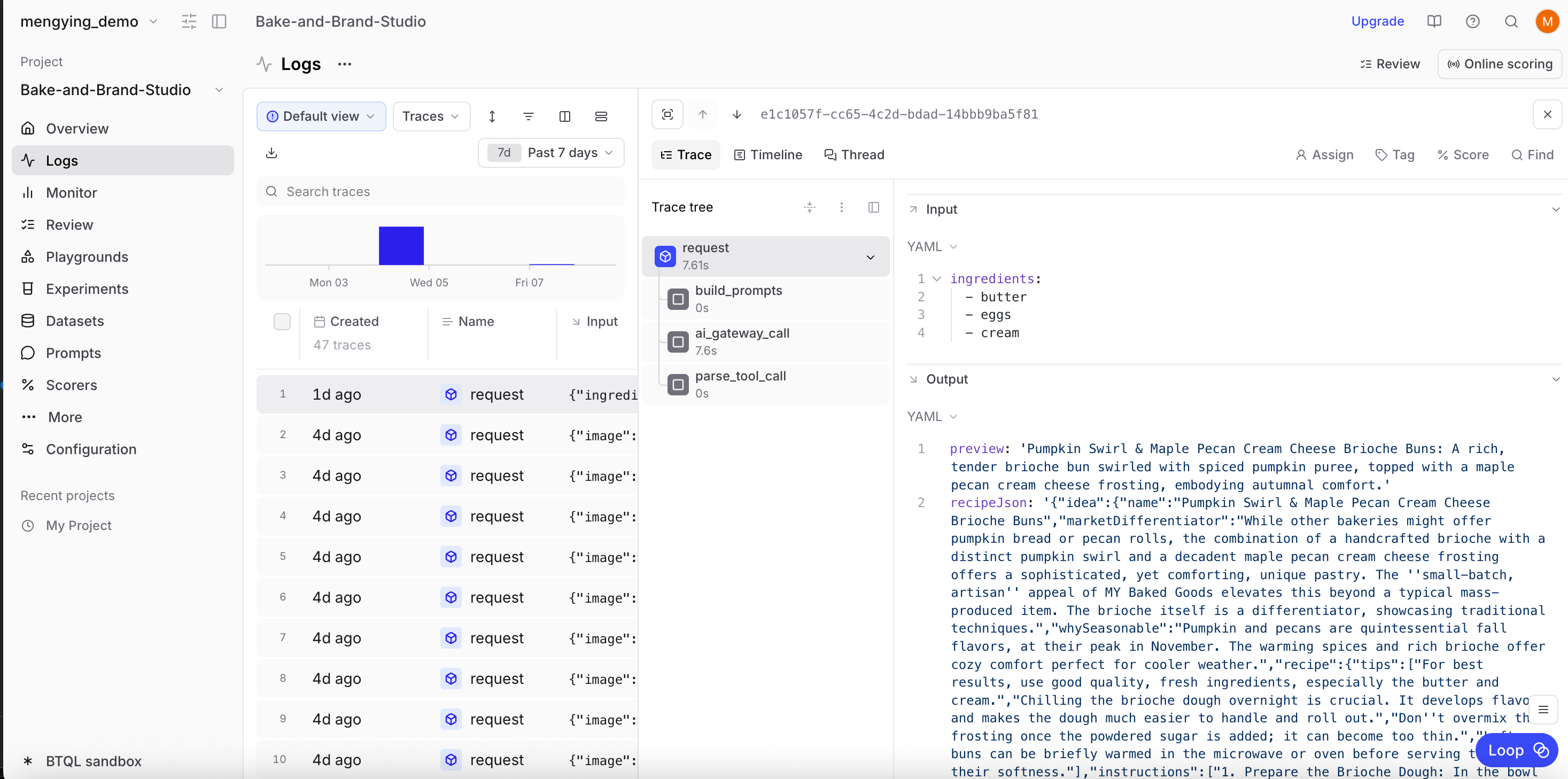
ai_gateway_call child span will show system and user prompts.
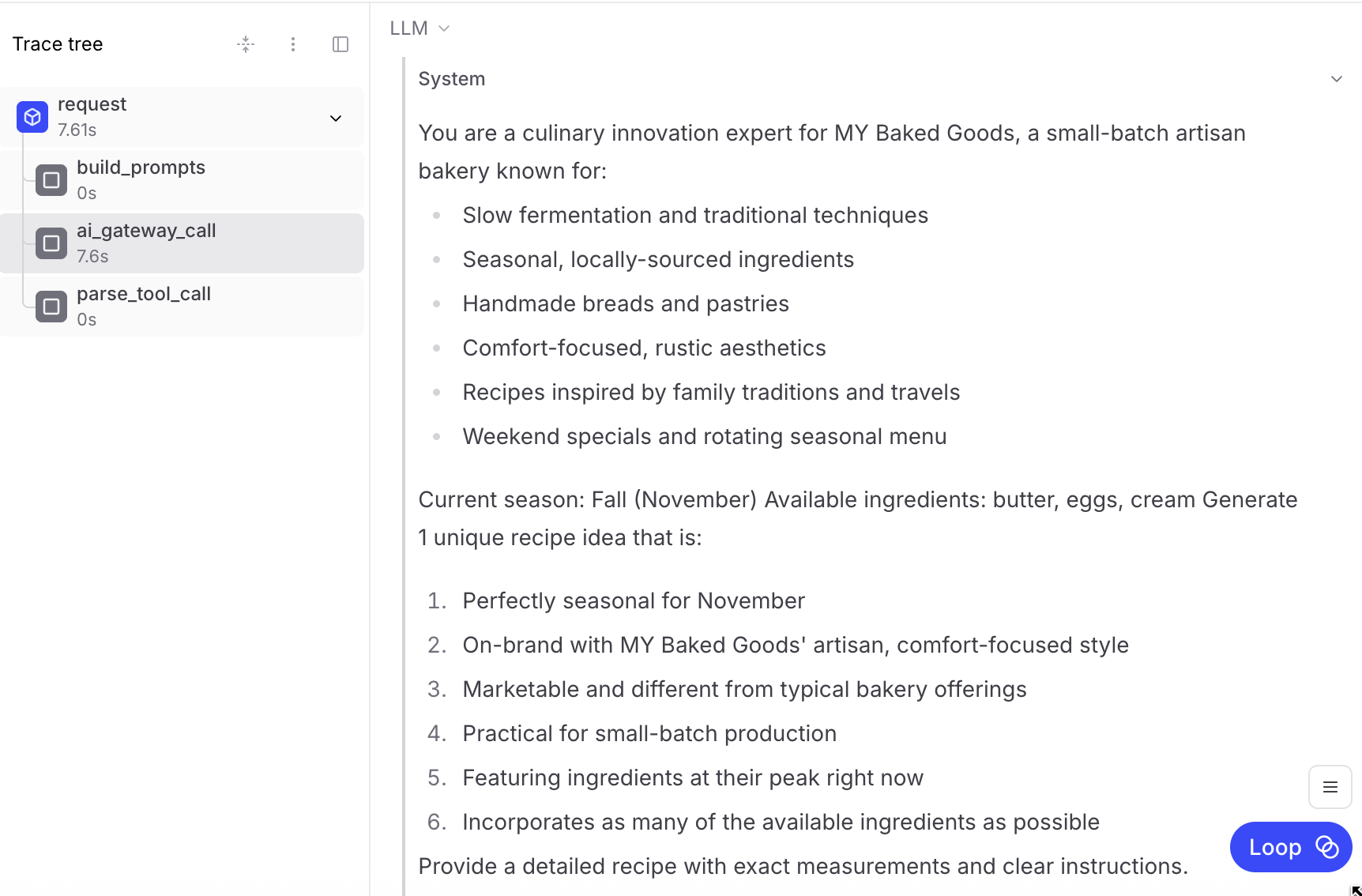
- Request inputs and outputs
- AI model interactions with prompts
- Processing steps with latency
- Complete request/response payloads
Running eval experiments
Once logging is live, you can run evals to compare prompt or agent changes and score results:- Create a playground directly from Logs
- Ask Braintrust’s AI assistant to add custom scorers
- Experiment with different models and prompts
- Compare results side-by-side
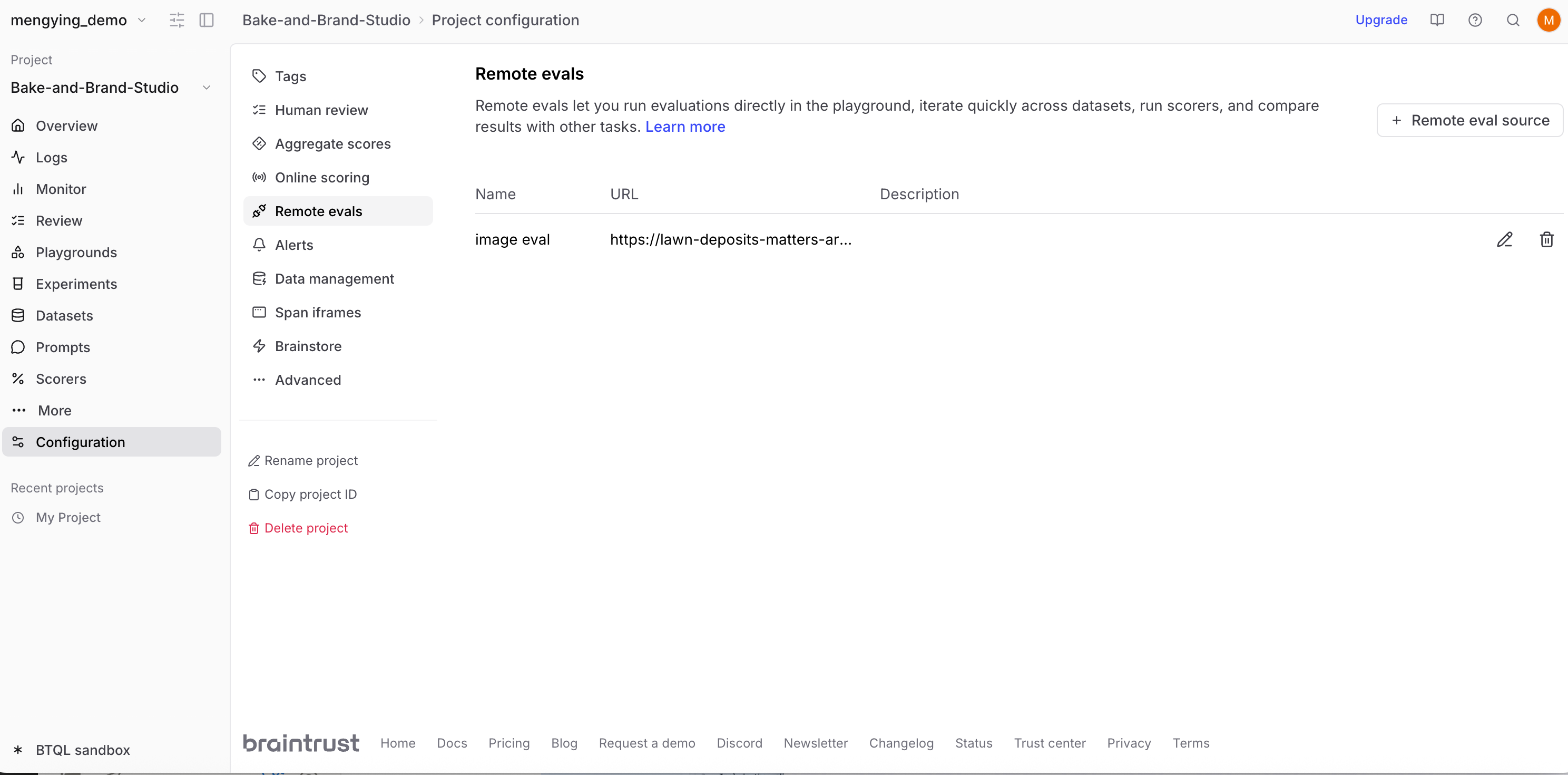
Running remote evals
You can use remote evals to tweak prompts or tool calls locally, then test your cloud function as if it were deployed.- Ask Lovable for the exact Supabase Edge Function URL and substitute it below
- Run a local dev server
- Expose it via Cloudflare Tunnel
- Register the tunnel URL in Braintrust
https://xyz-abc-123.trycloudflare.com):
Troubleshooting
You can ask Lovable to help you troubleshoot in the chat window.Traces not showing up
- Verify secret name in Supabase matches your code
- Ensure Braintrust
projectNameis exact - Look for “[Braintrust]” console messages
- Ensure every span calls
await span.end()
Images not displaying
- Log full base64 data URLs
- Keep payloads under ~10 MB per trace
- Use format:
data:image/png;base64,... - Don’t log booleans — include the actual data
Errors in logs
- Verify SDK import succeeded
- Check that API key is valid
- Ensure
asyncFlush: falseis set - Confirm outbound network access is allowed from Supabase Edge
Next steps
Now that you have a Lovable app with full observability and evaluation capabilities, you can:- Create custom scorers to evaluate AI quality against specific criteria
- Build evaluation datasets from production logs to continuously improve your app
- Use the playground to experiment with prompts before deploying changes
- Add more AI features to your Lovable app with confidence in their quality