Evaluating Gemini models for vision
With the AI proxy, evaluating the performance of leading image models like Gemini Pro 1.5 and Flash 1.5 is as simple as a one-line model change. Gemini can be used for any multimodal use cases, like document extraction and image captioning. To see how these models stack up, we put them to the test— read on to find out which vision model came out on top.
Gemini for document extraction
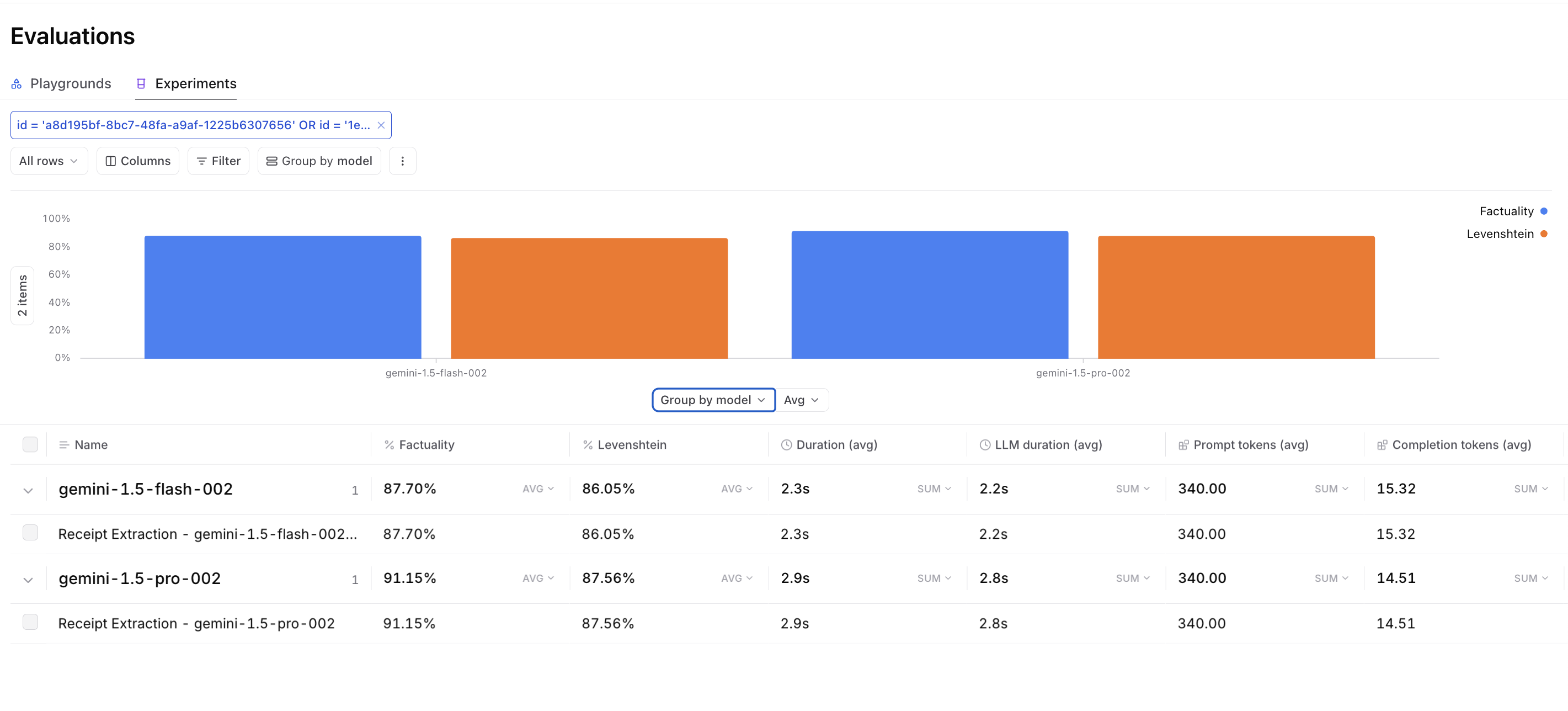
To understand Gemini's capabilities, we compared them to other state-of-the-art multimodal models using the receipt extraction cookbook. Besides swapping to Gemini, we used the same setup: the input is an image of a receipt, and the model extracts values for keys.
We used Gemini models (gemini-1.5-pro-002 and gemini-1.5-flash-002, specifically), alongside GPT-4o, Llama 3.2, and Pixtral 12B to assess accuracy, efficiency, and latency. Here's what we found:
| Model | Factuality | Levenshtein | Prompt tokens | Completion tokens | LLM duration |
|---|---|---|---|---|---|
| Gemini 1.5 Pro 002 | 91.15% | 87.56% | 340 tok | 14.511 tok | 2.80s |
| Gemini 1.5 Flash 002 | 87.70% | 86.05% | 340 tok | 15.32 tok | 2.24s |
| GPT-4o | 84.40% | 84.93% | 1223 tok | 12.06 tok | 13s |
| GPT-4o mini | 81.40% | 86.81% | 38052.40 tok | 12.31 tok | 11.6s |
| Llama 3.2 90B Vision | 79.10% | 77.52% | 89 tok | 14.45 tok | 4.8s |
| Llama 3.2 11B Vision | 56.10% | 52.78% | 89 tok | 11.31 tok | 4.8s |
| Pixtral 12B | 66.75% | 73.56% | 2364.51 tok | 19.22 tok | 13.8s |
Key takeaways
- Gemini models use significantly fewer tokens per image compared to the GPT models. For this particular eval, GPT-4o uses 3.5x the number of tokens per image of Gemini Pro and Flash 1.5, and GPT-4o mini uses 111x the number of tokens of the Gemini models.
- Levenshtein distance scores, a heuristic metric, are largely comparable between the Gemini 1.5 and GPT-4o models. Factuality, which is LLM based (using GPT-4o as the autorater), diverges more between the models, with Gemini 1.5 Pro and Flash 002 performing marginally better than GPT-4o and GPT-4o mini. We observed a maximum of 3% variance (89%-94% with Pro 1.5 and 84%-89% with Flash) when re-running the same evals with the Gemini models.
- The Gemini models process inputs faster than the GPT-4o models (due to more efficient tokenization) for this document extraction task.
- The number of completion tokens for this task is 20-25% higher with the Gemini models.
In summary, Gemini models were more token-efficient, faster at processing inputs, and slightly more accurate in factuality, though they generate more completion tokens compared to GPT-4o models.
Getting started with Gemini
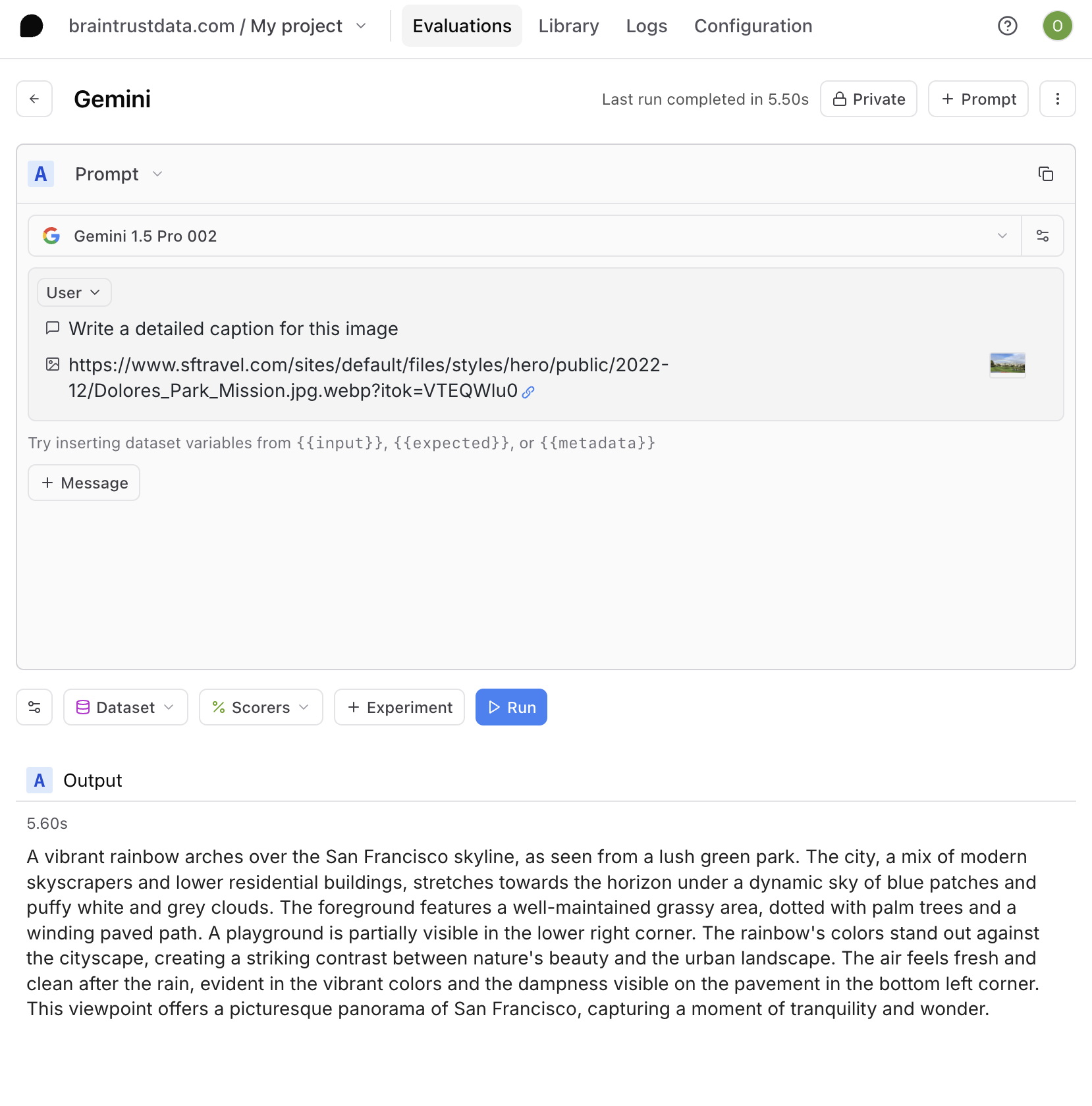
Given that the example above is based on a specific task and image domain, we encourage you to try Gemini through the proxy for your own use cases or other vision prompts. The proxy is standardized to OpenAI's interface, but you can query and run evals with the Gemini models using just a single-line model parameter change:
const client = new OpenAI({
baseURL: "https://api.braintrust.dev/v1/proxy",
apiKey: process.env.BRAINTRUST_API_KEY,
});
const prompt = "write a detailed caption for this image";
const img_path =
"https://www.sftravel.com/sites/default/files/styles/hero/public/2022-12/Dolores_Park_Mission.jpg.webp?itok=VTEQWlu0";
const model = "gemini-1.5-pro-002";
async function main() {
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: "user",
content: [{ type: "image_url", image_url: { url: img_path } }],
},
{ role: "user", content: prompt },
],
temperature: 0,
});
return response.choices[0].message.content;
}
main();
Want to see Gemini in action? You can use the playground to compare different models and prompts side by side.
Working with multimodal models
Every request through the AI proxy is logged to Braintrust for deeper insights into your performance and usage. Whether you’re exploring document extraction, image captioning, or other multimodal use cases, the proxy lets you integrate Gemini into your applications with just a single-line code change.
The playground also provides a way to experiment with Gemini’s multimodal capabilities, compare outputs across models, and fine-tune prompts to meet your specific needs. For a deeper dive into working with multimodal models and understanding traces, check out our detailed guide.