It's time to build reliable AI
Today, we're introducing Braintrust: the enterprise-grade stack for rapidly building and shipping AI products, without guesswork.
Over the last year, the AI space has rapidly evolved. Building anything from chatbots to question-answering or content generation systems used to require months of work. Today, these and more advanced tasks can be solved with a handful of API calls. At the same time, market demand for AI to be a core component of every business has skyrocketed—thanks in large part to ChatGPT, which demonstrated AI's potential to the world when it was released just 8 months ago.
The end of predictable software
In the mad dash to build with AI, it's become increasingly difficult to deliver high quality, reliable software products. Going from idea to production can be challenging (something I experienced first-hand building AI products at Impira and Figma). For example, how do you define what it means to be "100% correct" when summarizing text? And it only gets harder once you ship. The smallest change in code can have significant downstream effects—how can you be sure that you won't break things for your customers?
I've long had a personal connection to this problem. I started my career building a relational database system that powers critical processes at banks, telcos, and governments. I'll never forget a managing director at a bank warning me that his team would lose their jobs if our database lost data. Prioritizing quality and reliability has always been essential in software workflows. The same is true for AI, despite its inherently non-deterministic behavior. AI's spontaneous and unpredictable nature is what makes it such a great writing partner, programming assistant, and photo generator—but translating its behavior into meaningful quality metrics is incredibly challenging.
This is where Braintrust comes in. The faster you can test your AI software on real world examples, the faster you can iterate and improve it. Braintrust is like an operating system for engineers building AI software. It allows you to evaluate and improve your product, every single time you use it. Simply put, Braintrust helps you ship higher quality products, faster.
Automated evaluations you can trust
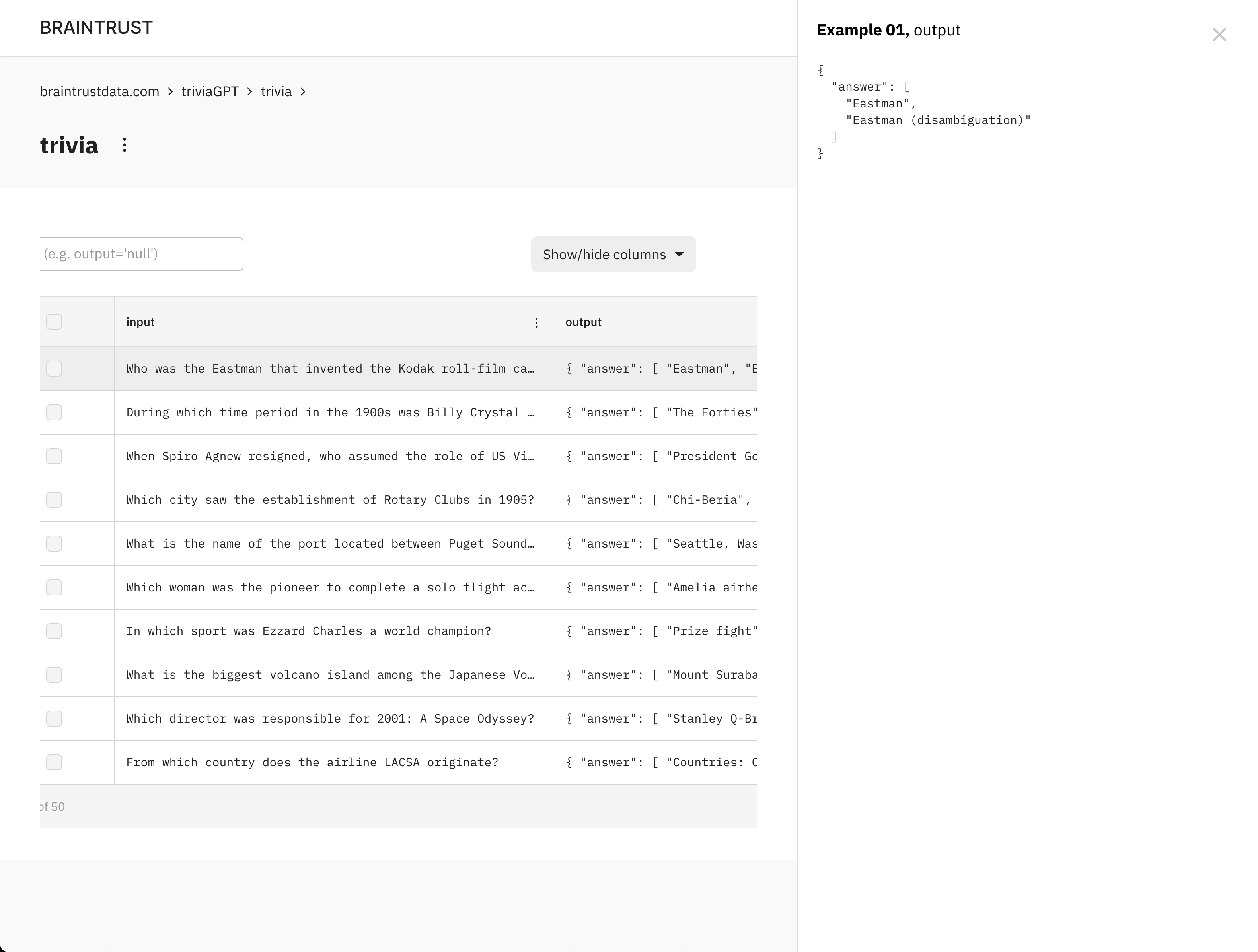
Robust evaluations enable teams to iterate much, much faster. We make it simple to score outputs, log evaluations, visualize them, interrogate failures, and track performance over time with a simple yet powerful UI. For example, you can instantly answer questions like "Which specific examples regressed on my change?", "Why did the model pick option A instead of B?", and "What happens if I try this new model?"

What does 90% accuracy actually mean? In Braintrust, you can click to see the examples that improved vs. regressed. You can see how values differ across experiments to debug issues.
Having this information readily available frees you to try out more changes and make informed decisions. While the premise is simple, implementing evaluations is no easy task. Our infrastructure eliminates the friction of logging, measuring, tracking, visualizing, and sharing evaluations, leaving space for you to focus on building and iterating your product.
Dataset management
It can be a lot of work to manage datasets. However, they're key to measuring how your application is performing, and they provide a shared source of truth that can drive experimentation. Braintrust makes it simple to capture new user examples from staging and production, evaluate them, and incorporate them into "golden" datasets. Datasets are automatically versioned, so you can make changes without risk of breaking evaluations that depend on them.
Additionally, we believe you should own your data. Braintrust can run within your cloud environment, on top of your existing data stack, so our servers never see your data. This architecture enables our customers to comfortably use Braintrust on their most important and IP-sensitive tasks, like leveraging datasets to fine-tune and evaluate custom models.
Collaborative playground for rapid testing
Prompt playgrounds have become a critical part of the AI development process, bringing together technical and non-technical users to experiment with and compare prompts. Our early users asked us for a native playground that would allow them to riff on their evaluations and datasets. And we built exactly that—in one click you can explore prompts over any dataset or prior experiment, try out new ideas, and even evaluate them.
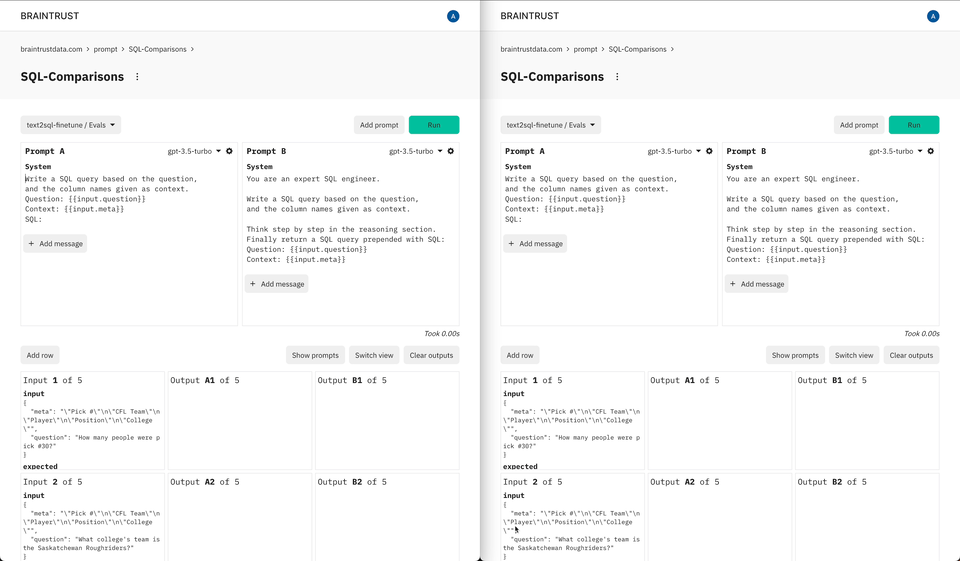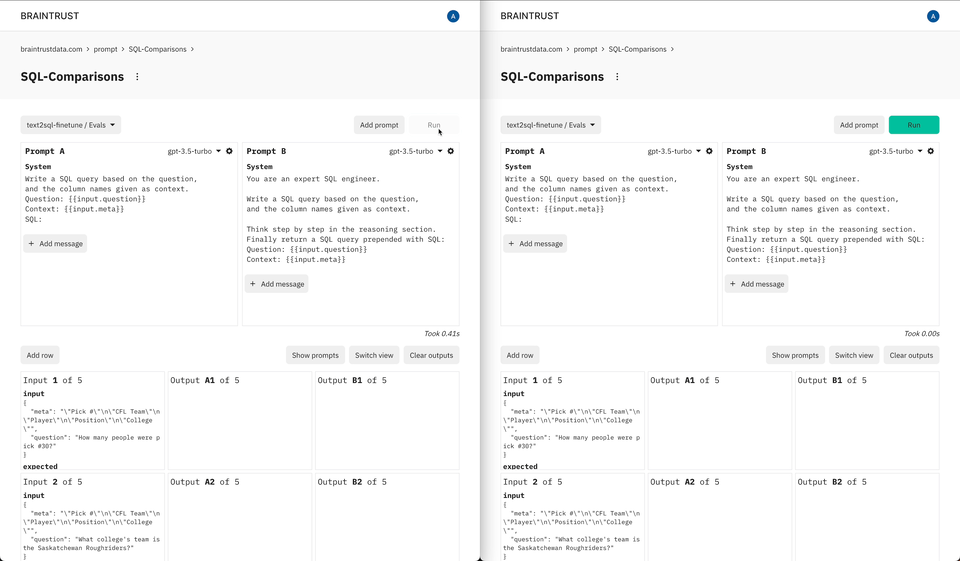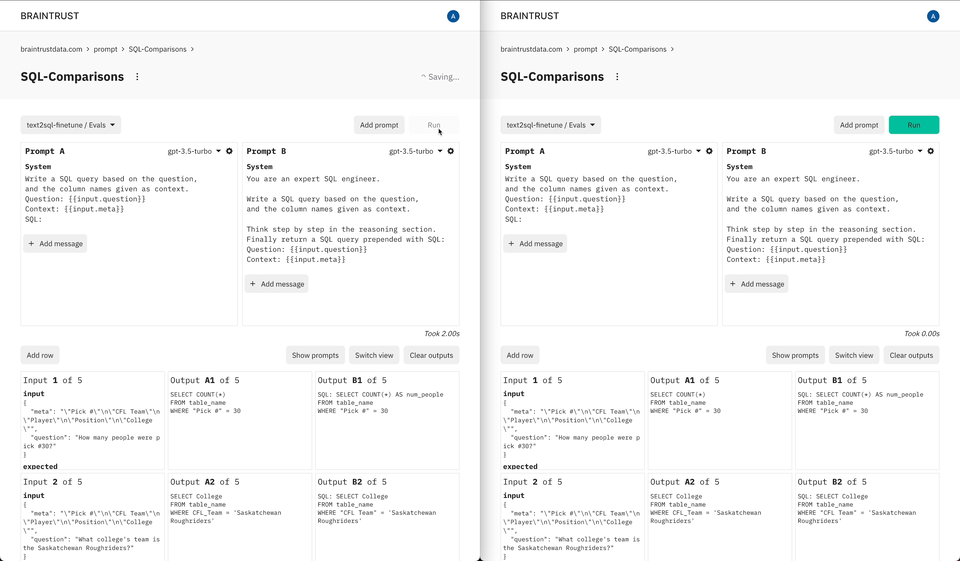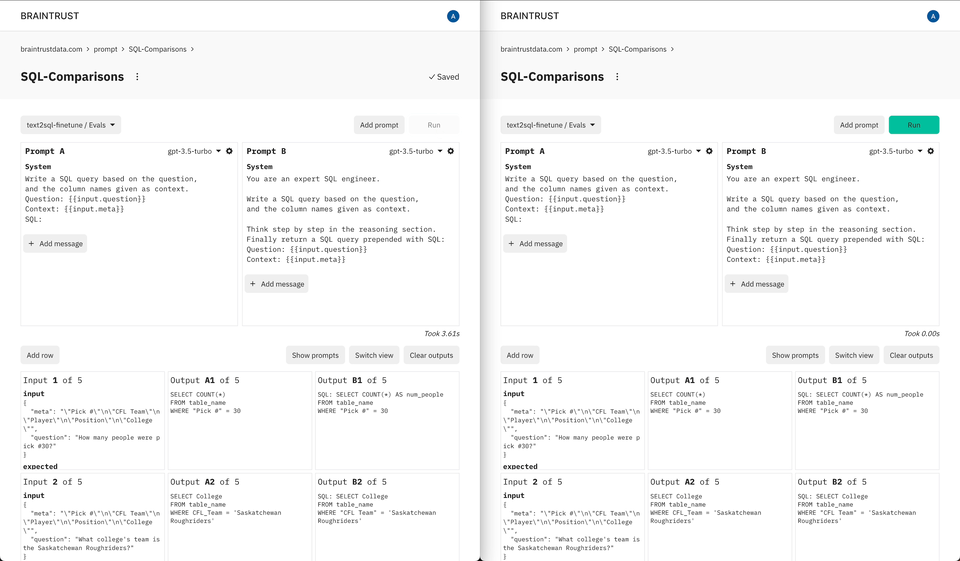
We believe that a new product development stack is forming around AI, and that by creating tools that integrate seamlessly together, we enable our customers to consistently stay at the forefront of this rapidly changing field. Braintrust's playground is the first of many features we'll introduce that natively integrate with other pieces of the platform and can run on-premises.
Tomorrow, together
Braintrust is already partnering with several enterprise customers at the forefront of AI.
- "Braintrust fills the missing (and critical!) gap of evaluating non-deterministic AI systems. We've used it to successfully measure and improve our AI-first products." - Mike Knoop, Co-founder & Head of AI at Zapier
- "We're now using a tool called Braintrust to monitor prompt quality over time and to evaluate whether one prompt or model is better than another. It's made it easy to turn iteration and optimization into a science." - David Kossnick, Head of AI Product at Coda
- "Testing in production is painfully familiar to many AI engineers developing with LLMs. Braintrust finally brings end-to-end testing to AI products, helping companies produce meaningful quality metrics." - Michele Catasta, VP of AI at Replit
Finally, I'm thrilled to be building Braintrust with an incredible group of people. I started the company with assistance from Elad Gil, who helped incubate the initial eval product and team with me. He backed Impira, my previous startup, and over the past six years we've developed a strong working relationship. Joining us on this exciting journey is Coleen Baik as founding designer, and Manu Goyal as founding engineer. David Song, who built the evaluation solutions at mem.ai and is a part of Elad's team, is helping us as well.
Elad and Alana of Base Case Capital are leading our initial funding round, along with incredible founders & executives including:
Get started for free
Everyone can get started with Braintrust for free. We recognize how important it is to be part of the development process from day one, so we are making these tools immediately accessible.
Additionally, Braintrust is free for open source projects and academic research. AI is largely a community-driven effort, and we want to support these efforts with tools that can help improve AI quality and reliability for everyone.
Sign up now, or check out our pricing page for more details.